Late-Bound Sagas: Why Your Agent Is Not an LLM in a Loop
Here is how a lot of agents are still written today:
def run_agent(task):
state = State(task)
while not state.is_terminal():
intent = llm.plan(state)
result = execute_tool(intent.tool)
state.append(result)
return state.final_answer()
Here is how it should be written:
@agent
def run_agent(task):
while not done(task):
intent = yield plan(task)
result = yield execute(intent)
task = yield append(task, result)
The syntax change is small. The runtime boundary is not. In the first version, your process owns execution state. In the second, the runtime does.
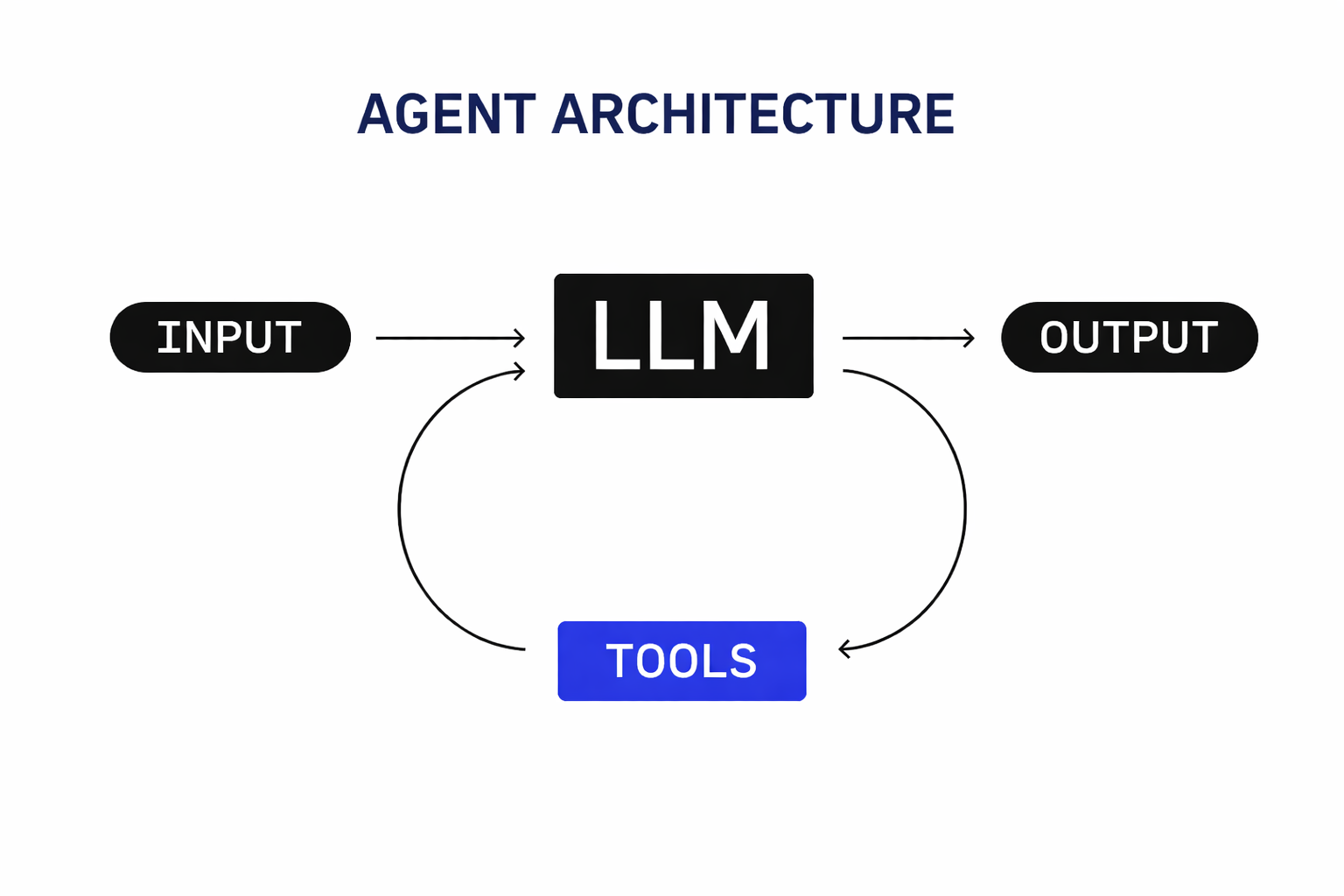
An agent is a saga that the model writes as it runs
Not a loop the model sits inside. That distinction, saga versus loop, is the difference between a demo and a system you can run a business on. It has a name: the Late-Bound Saga.
I’ve spent the last decade building Conductor, the durable-execution runtime we open-sourced in 2016 at Netflix. This post is what I’ve learned about how that kind of runtime has to change for agents, and why the shape of the answer is not what the durable-execution lineage has been building for the last ten years.
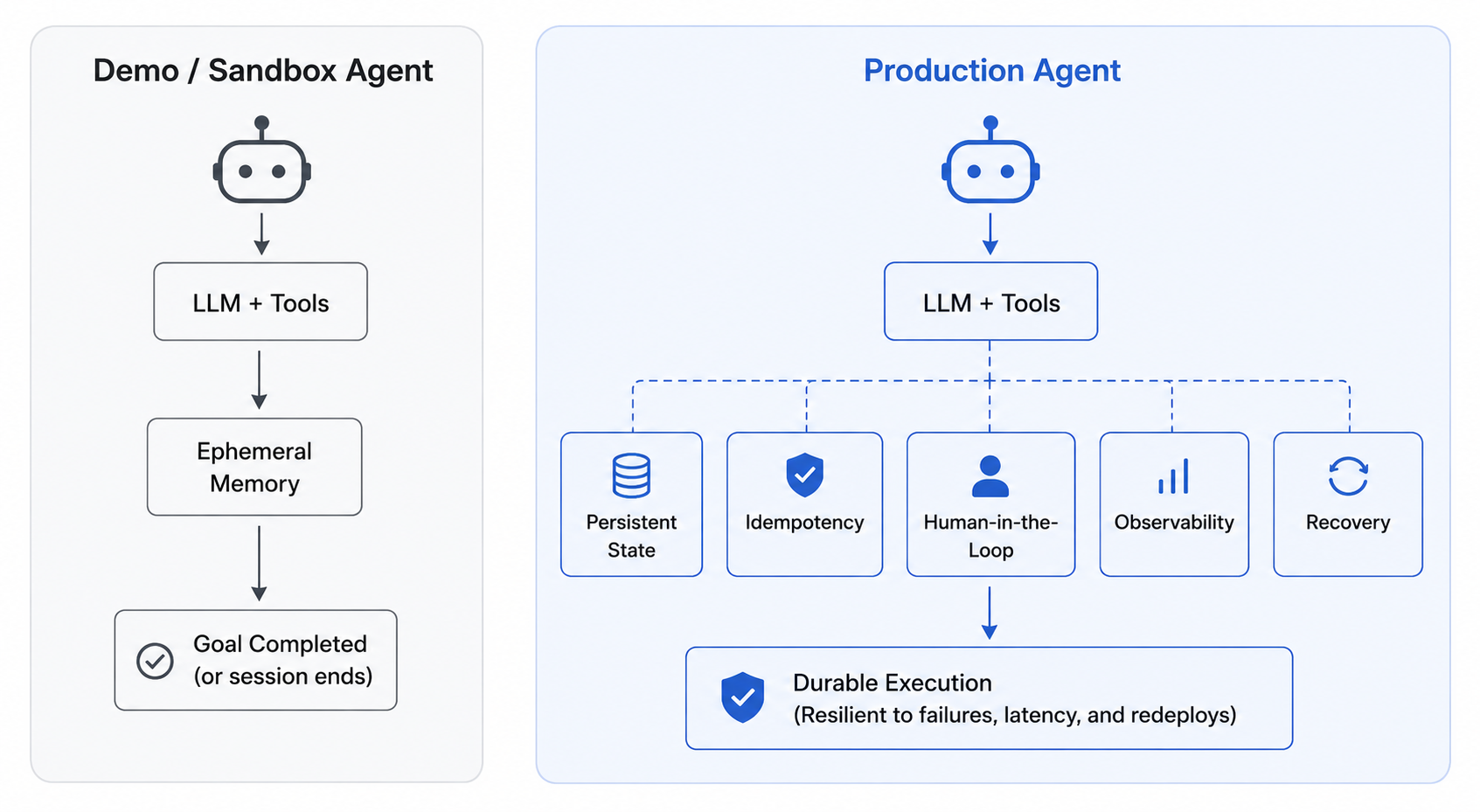
Durability is not continuity
My agent runs in a pod. I checkpoint to Postgres after every tool call. If the process dies, Kubernetes brings it back. I have durability. What else is there?
Your agent calls Stripe to charge a customer $4,000. The call succeeds. Before your code can write the row that says “Stripe call complete,” the pod gets evicted. Kubernetes restarts the pod. Your agent reads the last checkpoint, which says “about to call Stripe.” It calls Stripe again. You have just charged the customer $8,000.
Postgres did its job. Kubernetes did its job. Your checkpoint did its job. You still double-charged the customer.
The bug is not that anything failed. Durability means your data survives. Continuity means your program counter survives. The runtime knows which instruction you were about to execute, determines whether the side effect already ran, and avoids executing it again, no matter how many times the process dies between attempting it and recording it.
Your demo worked because it was twelve steps long
A 200-step agent run succeeds 13% of the time. Not because the model is wrong. Because of math.
Suppose every step succeeds with 99% reliability. A 20-step workflow succeeds 81% of the time. A 50-step workflow succeeds 60% of the time. A 100-step workflow succeeds 36% of the time. A 200-step workflow, what a serious multi-agent task looks like once you count sub-agent calls, succeeds 13% of the time.
The only tool the loop has to respond is to start over from the beginning, which doubles the token bill and reintroduces the same probability distribution on the retry.
The LLM should not execute anything
The fix is the strictest possible separation between two planes.
The LLM plans. It is a pure function from state to intent. It looks at the world and emits a description of what it would like to happen next. That description is data, not action.
The runtime executes. It receives intents from the planning plane, writes them to a persistent ledger before doing anything with them, performs the side effect against the real world, writes the result back, and only then asks the LLM what to do next. The ledger, not process memory, is the source of truth.
The LLM proposes; the runtime disposes.
An agent runtime has to provide at least four things a loop cannot:
a. Intent ledger
Records every proposed action before it executes, so “did this happen?” is answerable from outside the agent’s process.
b. Effectively-once execution of side effects
A crash between proposing an action and recording its result never causes the action to run twice.
c. Suspension and resumption across process boundaries
An agent waiting on a human, a webhook, or another agent consumes zero compute and survives infrastructure churn.
d. Out-of-band signal delivery
A supervisor, a human, or another agent can inject new context without killing the workflow.
The Late-Bound Saga
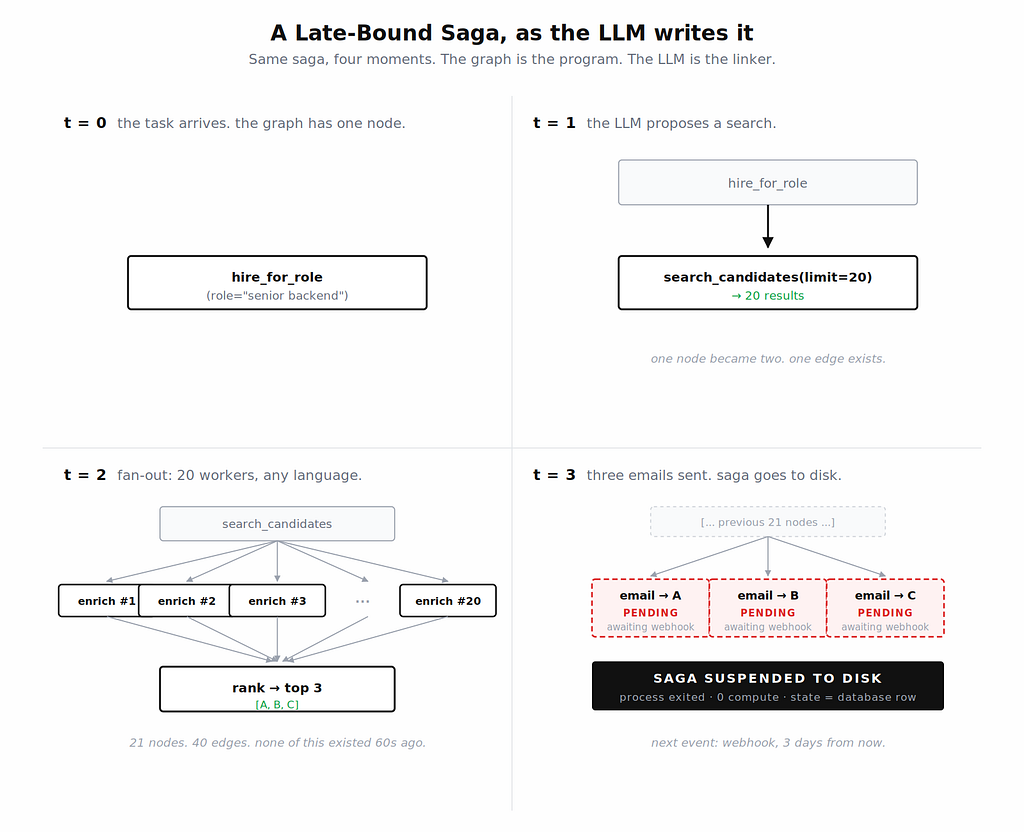
A Late-Bound Saga is a workflow whose execution graph does not exist when the workflow starts. The LLM synthesizes it edge by edge at runtime, and each edge is committed to a durable ledger at the moment it is proposed, before it executes.
The order matters. Not: LLM decides -> tool executes -> write down what happened. Instead: LLM decides -> write the intent -> tool executes -> write the result -> LLM sees the result.
The late-bound half gives you dynamism. The saga half gives you durability. You do not have to choose between the two.
What it looks like in motion
The agent’s task: find the three best candidates for the senior backend role, and schedule first-round interviews with each.
Step 1: the LLM proposes a search.
The runtime asks the LLM for an intent. It proposes:
search_candidates(role=“senior backend”, limit=20)
The runtime writes the intent, executes the search in a worker, writes the twenty results back.
Step 2: the fan-out.
The runtime asks again. The LLM proposes twenty parallel enrich_candidate calls. The runtime writes twenty pending intents, dispatches twenty workers, and waits for each to report back.
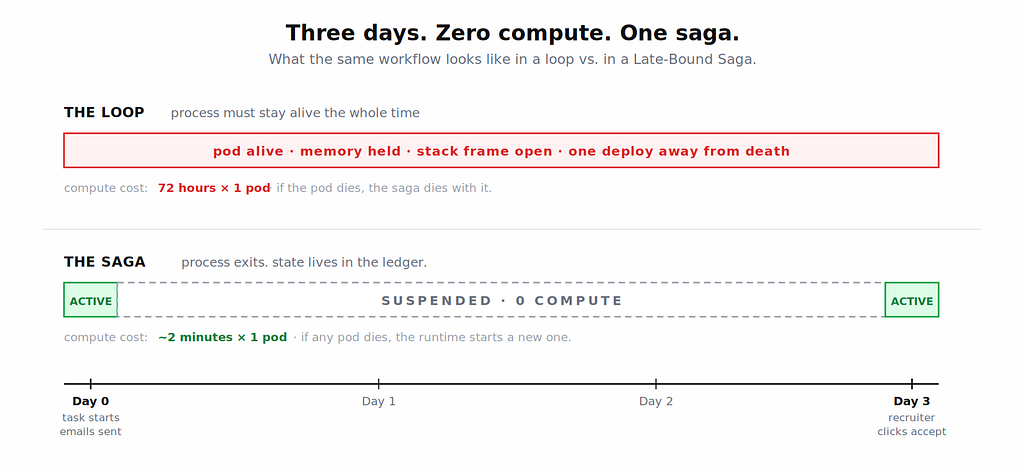
Step 3: the saga goes to sleep for three days.
The LLM ranks, selects three, and proposes three request_interview_slot calls. The runtime dispatches the emails, writes the three pending nodes, and suspends the entire saga to disk. The agent’s process exits. There is nothing running.
Three days later, a recruiter clicks accept. The webhook fires. The runtime looks up the saga, writes the result, and asks the LLM for the next intent.
Signals are cache invalidation for intent
Now suppose on day two, a supervisor agent tells the saga to abort. In the loop model, there is no agent to tell, because the process exited days ago.
In the Late-Bound Saga model, the runtime is the inbox. You send a signal to the saga’s ID. The runtime writes the signal, wakes the saga, and asks the LLM what to do. The LLM sees the cancellation, proposes a compensation sequence, and the runtime executes each step.
Think of a signal as cache invalidation for intent. The agent’s plan is a cache. The world is the source of truth. When the world changes, the cache has to be invalidated and rebuilt.
The runtime model, built into Agentspan
Agentspan sits on top of Conductor, the durable-execution runtime I open-sourced at Netflix in 2016. Conductor treats workers as protocol clients rather than SDK-bound processes, which means your planner can run in Python where the LLM ecosystem lives, your high-throughput data tool can run in Go, and your legacy underwriting model can stay in the JVM.
Agentspan is the layer that turns that substrate into an agent runtime.
from agentspan import agent, tool
@tool
def search_candidates(role: str, limit: int): ...
@tool
def enrich_candidate(candidate_id: str): ...
@tool
def req_interview_slot(candidate_id: str, recruiter_id: str): ...
@agent(model="claude-sonnet-4-6")
def hire_for_role(role: str, recruiter_id: str):
"""
Find the three best candidates for the given role and
schedule first-round interviews with each of them.
"""
That is the user-level program. The rest of the machinery lives where it belongs: in the runtime.
No loop. No state machine. No explicit call to the LLM. When you invoke hire_for_role("senior backend", "rec_42"), the runtime starts a saga, calls the LLM with the task and the available tools, writes the proposed intent to the ledger, dispatches the worker, writes the result back, and calls the LLM again.
The Monday morning experiment
Open the agent you are building at work. Find the loop. Every agent has one. Answer three questions, honestly.
One. If the process dies in the middle of the third iteration, what happens to any side effect that iteration had already started?
Two. If a human or another agent needs to tell this loop to stop and reconsider, how does the message get in?
Three. Six months from now, your agent does something weird at 3
on a Tuesday. Where do you go to find out exactly what it saw and exactly what it decided?If any of those made you flinch, that flinch is the gap between durability and continuity, between a loop and a saga, between an LLM that executes and an LLM that proposes.
An agent is not an LLM in a loop. An agent is a saga the model writes as it runs. The loop was a hack we built while we were waiting to figure out what agents actually were. It is time to write the runtime.