Three Reviewers, One PR, Zero Wait: Build a Parallel AI Agent Pipeline
This is Part 2 of an 8-part series covering every multi-agent strategy in Agentspan. Today: the parallel strategy, where multiple agents tackle the same input simultaneously.
In Part 1, we built a sequential pipeline where each agent’s output fed into the next: classifier >> responder >> escalation_checker. That works when steps depend on each other.
But some tasks do not need that dependency chain. A code review does not need the bug reviewer to finish before the security reviewer starts. They can all look at the same code at the same time.
Today, I will show you how to build a parallel code review pipeline with Agentspan. Three reviewers, one piece of code, all running simultaneously. Results arrive together, with no unnecessary waiting.
What is Agentspan
Agentspan is an orchestration layer for building, bringing, and observing AI agents as durable workflows.
- Build: define agents with the Agentspan SDK using
Agent,@tool, and multi-agent strategies. Agentspan compiles them into server-side workflows that survive crashes. - Bring: if you already use frameworks such as LangGraph, OpenAI Agents SDK, or Google ADK, you can pass those agents into Agentspan and add durability and orchestration on top.
- Observe: every execution is inspectable in the dashboard. You can see agent flows, inputs and outputs, tool calls, and token usage.
What we are building
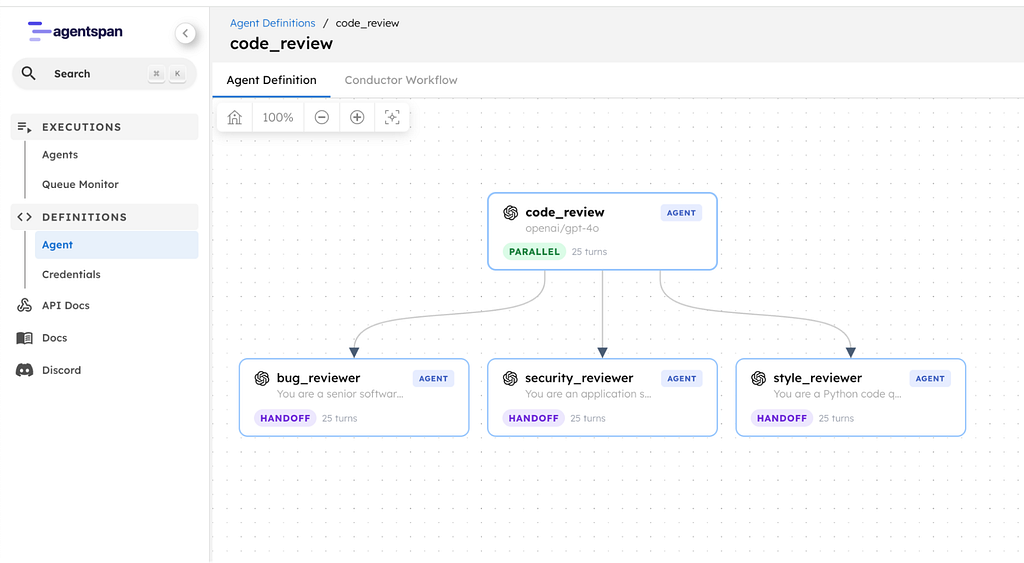
A parallel code review with three specialist agents:
- Bug Reviewer: finds logic errors, crashes, and unhandled edge cases
- Security Reviewer: finds injection flaws, insecure defaults, and OWASP issues
- Style Reviewer: checks type hints, docstrings, naming, and code quality
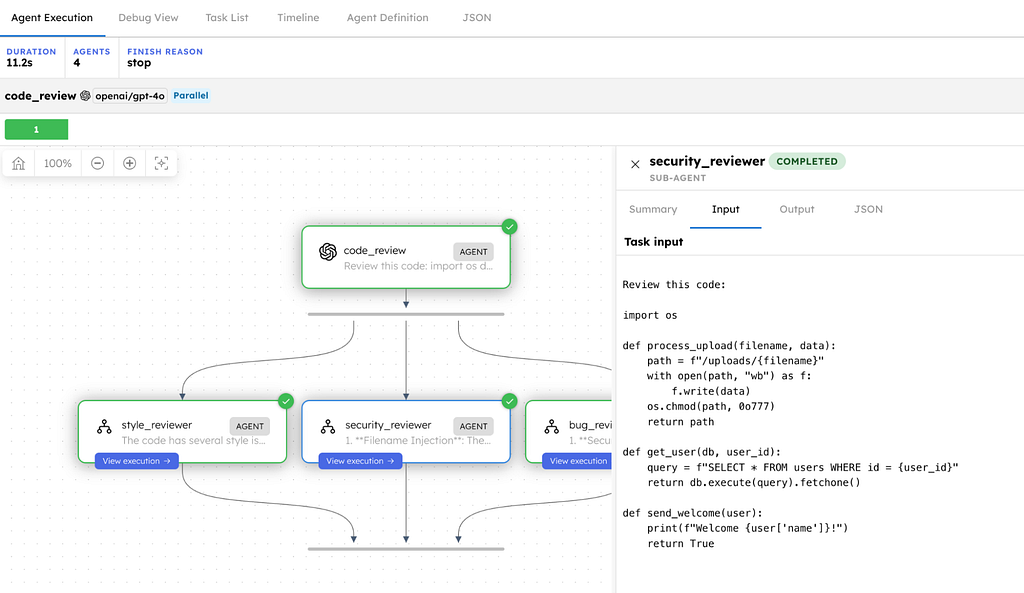
All three receive the same code. All three run at the same time. Their results are collected into sub_results, one per agent.
Code -> [Bug Reviewer] -> bug findings
-> [Security Reviewer] -> security findings
-> [Style Reviewer] -> style suggestions
This is the parallel strategy: agents fan out on the same input and their results arrive together.
Setup
Same as Part 1:
pip install agentspan
agentspan server start
This gives you a local Agentspan server with a visual dashboard at http://localhost:6767.
Defining the agents
Three agents, each with a different specialty:
from agentspan.agents import Agent, AgentRuntime, Strategy
bug_reviewer = Agent(
name="bug_reviewer",
model="openai/gpt-4o",
instructions=(
"You are a senior software engineer reviewing code for bugs. "
"Read the ACTUAL code carefully. Only report issues you can "
"point to in specific lines. Quote the exact code and explain "
"what's wrong.\n\n"
"Look for: logic errors, unhandled edge cases, crashes, and "
"incorrect behavior.\n\n"
"If the code has no bugs, say 'No bugs found.' "
"Do NOT invent issues. Do NOT give generic advice."
),
)
security_reviewer = Agent(
name="security_reviewer",
model="openai/gpt-4o",
instructions=(
"You are an application security engineer reviewing code for "
"vulnerabilities. Read the ACTUAL code carefully. Only report "
"vulnerabilities you can point to in specific lines.\n\n"
"Look for: injection flaws, insecure defaults, data exposure, "
"missing input validation, OWASP Top 10 issues. Rate each "
"finding as Critical, High, Medium, or Low.\n\n"
"If the code has no security issues, say 'No security issues "
"found.' Do NOT invent vulnerabilities. Do NOT give generic "
"security advice."
),
)
style_reviewer = Agent(
name="style_reviewer",
model="openai/gpt-4o",
instructions=(
"You are a Python code quality reviewer. Read the ACTUAL code "
"carefully. Only report style issues you can point to in "
"specific lines.\n\n"
"Look for: missing type hints, missing docstrings, hardcoded "
"values, print vs logging, naming issues, readability.\n\n"
"If the code style is good, say 'Code style looks good.' "
"Do NOT invent issues. Do NOT give generic advice."
),
)
Same Agent class as Part 1. Same model, same instructions pattern. The difference is what comes next.
The parallel strategy
Instead of >>, we wrap the agents in a parent agent with Strategy.PARALLEL:
review = Agent(
name="code_review",
model="openai/gpt-4o",
agents=[bug_reviewer, security_reviewer, style_reviewer],
strategy=Strategy.PARALLEL,
)
All three agents run simultaneously on the same input. Compare this to sequential:
# Sequential: each waits for the previous one
pipeline = bug_reviewer >> security_reviewer >> style_reviewer
# Parallel: all run at the same time
review = Agent(
name="code_review",
model="openai/gpt-4o",
agents=[bug_reviewer, security_reviewer, style_reviewer],
strategy=Strategy.PARALLEL,
)
Same agents, different strategy. The sequential version takes about 3x as long because each reviewer waits for the one before it. The parallel version takes as long as the slowest reviewer, roughly 1x.
The code to review
Let us feed it a short Python script with a mix of bugs, security issues, and style problems:
code = """
import os
def process_upload(filename, data):
path = f"/uploads/{filename}"
with open(path, "wb") as f:
f.write(data)
os.chmod(path, 0o777)
return path
def get_user(db, user_id):
query = f"SELECT * FROM users WHERE id = {user_id}"
return db.execute(query).fetchone()
def send_welcome(user):
print(f"Welcome {user['name']}!")
return True
"""
Three functions, each with problems that a different reviewer would catch. The bug reviewer, security reviewer, and style reviewer each have something to find, but they do not need each other’s output to do their job.
Running the review
with AgentRuntime() as runtime:
result = runtime.run(review, code)
for agent_name, sub in result.sub_results.items():
print(f"\n{'=' * 50}")
print(f" {agent_name}")
print(f"{'=' * 50}")
print(sub)
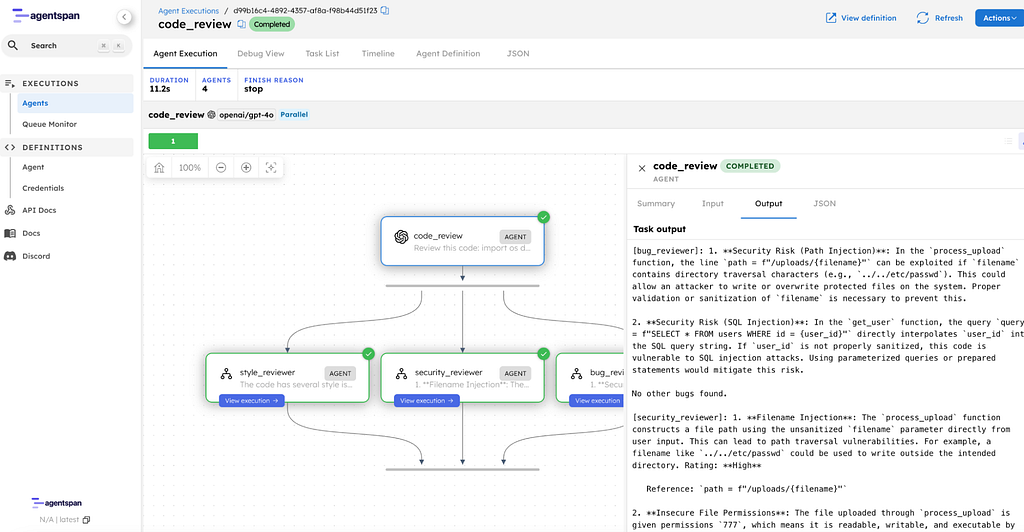
The key difference from Part 1 is result.sub_results. In a sequential pipeline, you get one final output. In a parallel pipeline, you get a dictionary with one entry per agent.
Bug Reviewer
1. Security Risk (Path Injection): In the process_upload function,
the line path = f"/uploads/{filename}" can be exploited if
filename contains directory traversal characters (e.g.,
../../etc/passwd). This could allow an attacker to write or
overwrite protected files on the system. Proper validation or
sanitization of filename is necessary to prevent this.
2. Security Risk (SQL Injection): In the get_user function, the
query query = f"SELECT * FROM users WHERE id = {user_id}"
directly interpolates user_id into the SQL query string. If
user_id is not properly sanitized, this code is vulnerable to
SQL injection attacks. Using parameterized queries or prepared
statements would mitigate this risk.
No other bugs found.
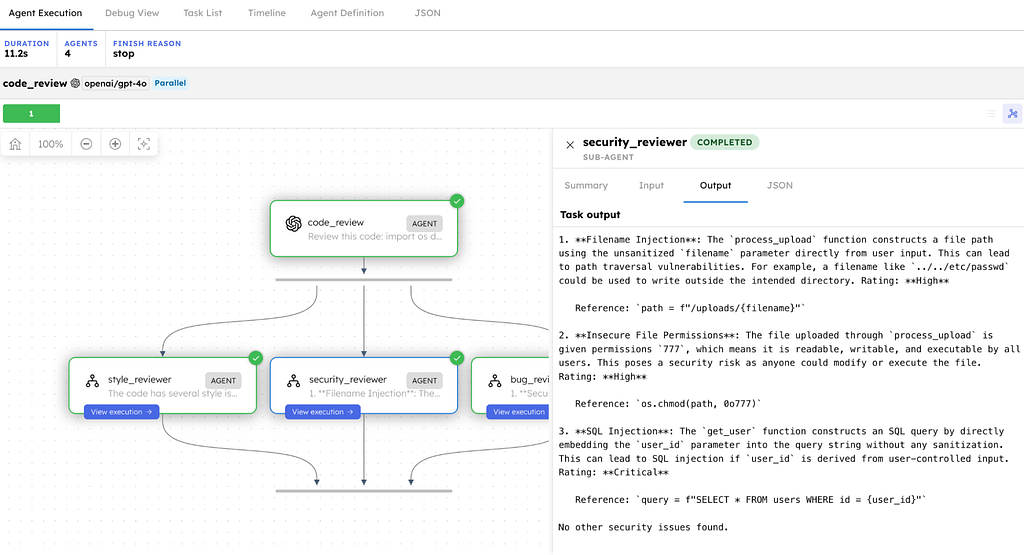
Security Reviewer
1. Filename Injection: The process_upload function constructs a file
path using the unsanitized filename parameter directly from user
input. This can lead to path traversal vulnerabilities. For
example, a filename like ../../etc/passwd could be used to write
outside the intended directory. Rating: High
Reference: path = f"/uploads/{filename}"
2. Insecure File Permissions: The file uploaded through
process_upload is given permissions 777, which means it is
readable, writable, and executable by all users. This poses a
security risk as anyone could modify or execute the file.
Rating: High
Reference: os.chmod(path, 0o777)
3. SQL Injection: The get_user function constructs an SQL query by
directly embedding the user_id parameter into the query string
without any sanitization. This can lead to SQL injection if
user_id is derived from user-controlled input. Rating: Critical
Reference: query = f"SELECT * FROM users WHERE id = {user_id}"
No other security issues found.
Style Reviewer
1. Missing Type Hints:
- process_upload is missing type hints for its parameters and
return value.
- get_user is missing type hints for its parameters and return
value.
- send_welcome is missing type hints for its parameter and
return value.
2. Missing Docstrings:
- process_upload lacks a docstring explaining its purpose.
- get_user lacks a docstring explaining its purpose.
- send_welcome lacks a docstring explaining its purpose.
3. Hardcoded Values:
- In process_upload, the path "/uploads/" and the permissions
0o777 are hardcoded.
4. Print vs Logging:
- send_welcome uses print() to output text, which is generally
discouraged in favor of using a logging framework.
Three different perspectives, all from the same code, all produced simultaneously. The bug reviewer found path injection and SQL injection, then said “no other bugs found.” The security reviewer rated each vulnerability by severity and quoted the exact lines. The style reviewer focused on code quality without inventing issues. Each brought a different lens, and where they overlap, such as SQL injection, their analysis differs.
Sequential vs Parallel: when to use which
Sequential (>>)
- Use when: each step depends on the previous one
- Execution: one at a time, in order
- Speed: sum of all agent times
- Output: single final result
- Example: Classify -> respond -> escalate
Parallel (Strategy.PARALLEL)
- Use when: steps are independent
- Execution: all at once
- Speed: time of the slowest agent
- Output: sub_results dict, one per agent
- Example: bug check + security check + style check
The rule is simple: if agent B needs agent A’s output, use sequential. If they can work independently, use parallel.
How durability works
The parallel pipeline compiles into a durable server-side workflow, same as the sequential pipeline from Part 1. If your process crashes while two reviewers are done and one is still running:
- The two completed results are persisted on the server.
- You restart your script.
- Only the third reviewer re-runs.
- Results are collected and returned.
No wasted API calls. No re-running agents that already finished.
Composability
You can mix parallel and sequential in the same pipeline:
# Run all three reviews in parallel, then summarize sequentially
review = Agent(
name="code_review",
model="openai/gpt-4o",
agents=[bug_reviewer, security_reviewer, style_reviewer],
strategy=Strategy.PARALLEL,
)
summarizer = Agent(
name="summarizer",
model="openai/gpt-4o",
instructions=(
"Combine the three reviews into a single verdict: "
"APPROVE, REQUEST CHANGES, or NEEDS DISCUSSION."
),
)
pipeline = review >> summarizer
Parallel fan-out, then sequential summarization. Same Agent class, same >> operator, strategies compose naturally.
Going further: connect to GitHub
The hardcoded code snippet is fine for learning Strategy.PARALLEL. In production, you would pull a real PR diff from GitHub and post the review back. Here is how.
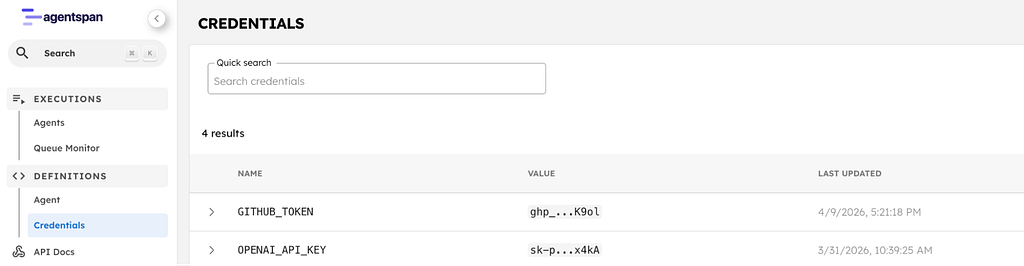
Store your credentials
In the Agentspan dashboard at localhost:6767, go to Credentials and add:
Name: GITHUB_TOKEN
Value: Your GitHub personal access token (needs repo scope)
The tools
Two tools: one to fetch the PR diff, one to post the review.
from agentspan.agents import tool
import os
import requests
GITHUB_API = "https://api.github.com"
@tool(credentials=["GITHUB_TOKEN"])
def get_pr_diff(repo: str, pr_number: int) -> dict:
"""Fetch the diff for a GitHub pull request. repo format: owner/repo."""
token = os.environ["GITHUB_TOKEN"]
resp = requests.get(
f"{GITHUB_API}/repos/{repo}/pulls/{pr_number}",
headers={
"Authorization": f"Bearer {token}",
"Accept": "application/vnd.github.v3.diff",
},
)
pr_info = requests.get(
f"{GITHUB_API}/repos/{repo}/pulls/{pr_number}",
headers={"Authorization": f"Bearer {token}"},
).json()
return {
"title": pr_info.get("title", ""),
"description": pr_info.get("body", ""),
"diff": resp.text[:10000],
"files_changed": pr_info.get("changed_files", 0),
"additions": pr_info.get("additions", 0),
"deletions": pr_info.get("deletions", 0),
}
@tool(credentials=["GITHUB_TOKEN"])
def post_pr_review(repo: str, pr_number: int, body: str) -> dict:
"""Post a review comment on a GitHub pull request."""
token = os.environ["GITHUB_TOKEN"]
requests.post(
f"{GITHUB_API}/repos/{repo}/pulls/{pr_number}/reviews",
headers={
"Authorization": f"Bearer {token}",
"Accept": "application/vnd.github.v3+json",
},
json={"body": body, "event": "COMMENT"},
)
return {"status": "posted", "pr_number": pr_number}
Wire them in
The three reviewers stay the same. Add a fetcher to pull the PR diff and a summarizer that combines the reviews and posts to GitHub:
fetcher = Agent(
name="pr_fetcher",
model="openai/gpt-4o",
instructions=(
"You are a helper that fetches PR diffs. Call the get_pr_diff "
"tool and return the COMPLETE diff verbatim as your output."
),
tools=[get_pr_diff],
)
summarizer = Agent(
name="summarizer",
model="openai/gpt-4o",
instructions=(
"You are a tech lead. Given three code review outputs (bugs, "
"security, style), combine them into a single PR review comment "
"in markdown with sections: ## Bugs, ## Security, ## Style, "
"## Verdict (APPROVE / REQUEST CHANGES / NEEDS DISCUSSION)."
),
)
# Sequential: fetch diff -> parallel review -> summarize
pipeline = fetcher >> review >> summarizer
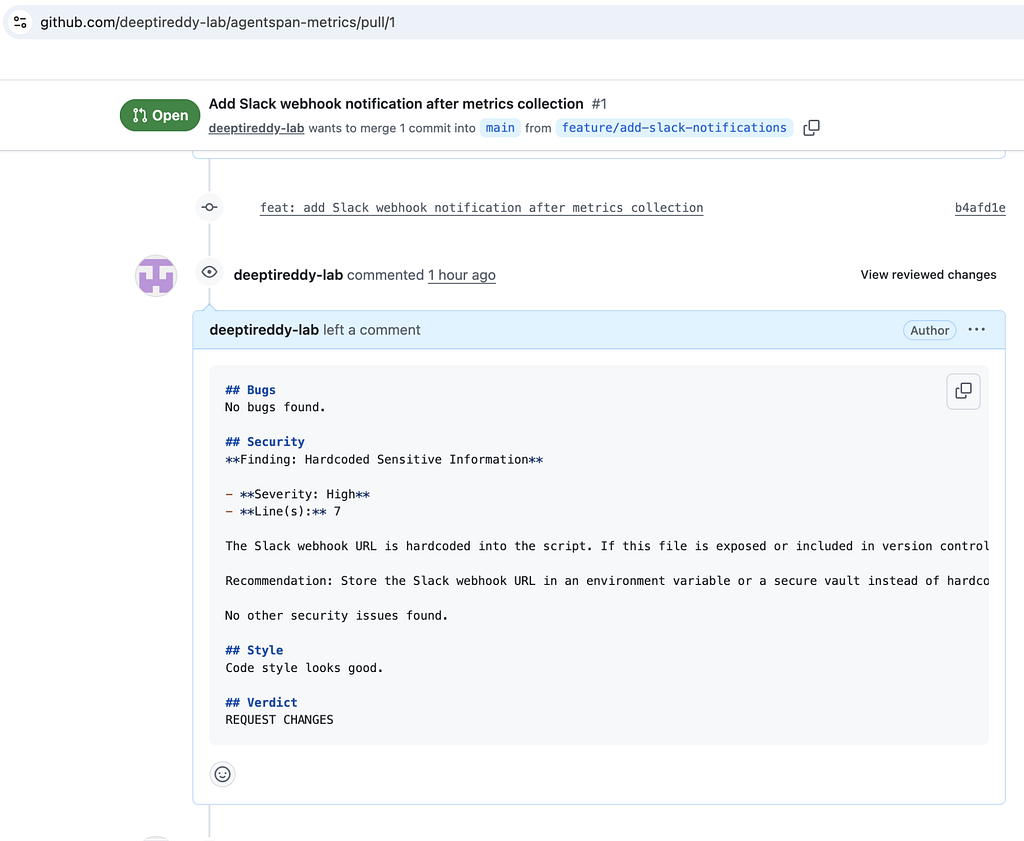
That gives you the full loop: fetch PR -> three parallel reviews -> summarize -> post review comment.
Try it
pip install agentspan
agentspan server start
python 07_parallel_agents.py
For the GitHub integration version:
- Add
GITHUB_TOKENin the Agentspan dashboard on the Credentials page. - Update the repo and PR number in your script to point at your own repository and pull request.
- Run the review flow.
- GitHub: github.com/agentspan/agentspan
- Python examples: sdk/python/examples/07_parallel_agents.py
- Docs: agentspan.ai/docs
- Discord: discord.com/invite/ajcA66JcKq
What’s next
Part 3: The Handoff Strategy - the LLM decides which agent to delegate to. A router that thinks, not just matches. Same Agent class, different strategy.