Why we built Agentspan: the production agent problem nobody wants to talk about
I’ve watched a lot of AI agent demos over the past two years. They almost always work. The demo is controlled, the inputs are predictable, the happy path is pre-tested, the LLM behaves. It’s impressive. Then you take that agent to production, and within a week you’re getting paged.
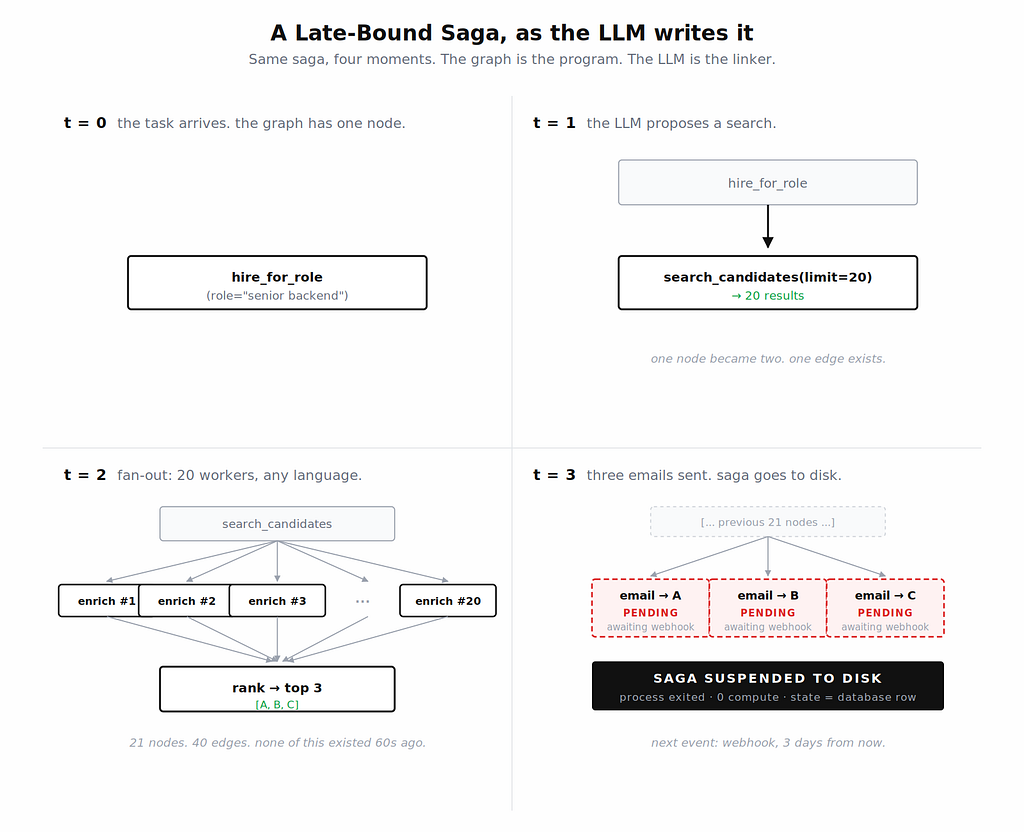
The agent dies mid-run. You restart it. It dies somewhere else. You’re debugging a non-deterministic system that fails differently every time, with no clear picture of what the agent was doing when things went wrong. And every restart means re-running all the steps that already completed, burning time and API tokens you already paid for.
I want to be specific about what’s happening here, because I don’t think it’s talked about honestly enough.
This is not a code quality problem
The natural instinct is to blame the agent code. Add better error handling. Catch more exceptions. Add retry logic. But that’s not really the issue.
The issue is that most agent frameworks run your agent inside a Python process and hope it finishes. If the process dies, for any reason, you lose everything. The execution state lives in memory. There’s nothing to pick up.
Some frameworks try to address this with checkpointing. You write state to Postgres or Redis periodically, so if things crash you can resume from the last checkpoint. That’s better than nothing, but it’s not what most people think it is. LangGraph’s own documentation describes this as fault tolerance that lets you “restart your graph from the last successful step.” But checkpoints are saved between nodes, not inside them. In a typical agent loop, the reasoning node is the agent — it’s the node making all the tool calls. If that node fails after 18 tool calls, the last checkpoint was saved before the node began. All 18 run again. Agentspan runs tool call 19.
The deeper problem is that agents are fundamentally harder than regular software in ways that make process-based execution brittle. Regular software is deterministic. Given the same inputs, you get the same outputs. You can test every path. You can reproduce bugs reliably.
Agents don’t work like this. An agent starts a task without knowing what it will need to do to finish it. It decides at each step based on what it finds, what tools return, what the LLM reasons, and what paths are available. The execution path is dynamic. This means agents hit edge cases at a much higher rate than typical software, because every run is different. Combine that with external API dependencies, LLM variability, and real-world inputs you can’t fully anticipate, and you have a system that will fail in production in ways your testing never surfaced.
And users hold agents to a higher bar, not lower. When a feature breaks, it’s a bug. When an agent fails, the whole thing feels unreliable.
The insight that led us to build Agentspan
Conductor is the workflow engine Netflix open sourced, and we’ve been working with it for years. Today that execution model shows up in production systems at companies including LinkedIn and United Wholesale Mortgage. We’ve seen what durable execution at scale looks like and what it takes to make complex processes reliable under real-world conditions.
What kept jumping out: the way an agent executes is structurally the same thing as a dynamic workflow.
Think about what actually happens during an agent run. The LLM looks at the task and decides what to do first. It calls a tool, looks at the result, and decides what to do next. That decision changes based on what came back. New steps get added mid-run that weren’t planned at the start. The execution path is built incrementally, step by step, based on what the agent finds.
That’s a dynamic workflow. Not a fixed, pre-compiled pipeline, a workflow that builds itself as it runs.
Conductor was designed for exactly this. You don’t need to recompile your execution plan when the LLM takes an unexpected path. You don’t need to know upfront all the steps an agent will take.
Conductor handles dynamic execution natively. It’s what the system was built for, at a scale where reliability wasn’t optional.
Most agent frameworks were designed by people thinking about agent intelligence, how agents reason, how they use tools, how they handle multi-agent coordination. That’s important work. But the execution layer underneath got less attention. A Python loop that runs until it’s done is fine for demos. It’s not fine for production.
What we actually built
Agentspan decouples two things that most frameworks conflate: how you express an agent and how the agent executes.
When you build agents, you think in terms of agents, tools, guardrails, and token budgets. You don’t want to think about workflow tasks, execution graphs, or distributed workers. So we give you an API that matches how developers think about agents. You define an agent, you define its tools, you run it.
Underneath, Agentspan compiles your agent definition into a Conductor workflow and executes it on the Agentspan server. Each tool call becomes a durable task. The server manages state, execution, retries, and recovery independently of your Python process. If your process crashes or gets recycled, the agent keeps running on the server. When you bring a worker back up, it picks up from the exact step where it left off. Not from the beginning.
This isn’t checkpointing. The completed steps are done. The LLM doesn’t reconsider them. The API calls don’t happen again. The next tool call in the sequence runs, and the agent continues.
Observability comes with this model for free. Because every step is a server-side task, every tool call, every LLM interaction, every decision is logged and visible. When something goes wrong in production, you can look at the exact execution and see what happened, not just that the agent failed, but which step failed, what the LLM was doing before it, and what the tool returned. That changes debugging from guesswork to diagnosis.
Human-in-the-loop and guardrails are also built into the execution model, not bolted on. A tool that requires human approval pauses the workflow at the server level. The pause can last hours or days, the state is held durably, and the agent continues when a human acts. A guardrail that catches a problem triggers a retry within the workflow, not a restart of the whole thing.
One thing we were deliberate about: you don’t have to change how you write agents
If you’re using LangGraph today, you keep using LangGraph. If you’re using the OpenAI Agents SDK, you keep using it. CrewAI and Google ADK work the same way. You pass your existing agent to Agentspan’s runtime and it becomes the execution layer underneath. Your agent logic, your tool definitions, and your framework choices stay the same.
What changes is what happens when your process dies, when you need a human to approve an action, or when you need to see exactly what your agent did three days ago.
We made this choice because developers have already invested in frameworks like LangGraph, the OpenAI Agents SDK, CrewAI, and Google ADK. Agentspan sits underneath that work as the execution layer, so teams can keep the agent code they already have and change how it runs in production.
What it looks like in practice
Here’s the simplest version. You define an agent and its tools, and run it:
from agentspan.agents import Agent, AgentRuntime, tool
@tool
def search_web(query: str) -> str:
"""Search the web for information."""
# Your implementation goes here.
return f"Results for: {query}"
agent = Agent(
name="research-agent",
model="openai/gpt-4o-mini",
instructions=(
"Research the topic thoroughly. "
"Call the search tool multiple times with specific queries."
),
tools=[search_web],
)
with AgentRuntime() as runtime:
result = runtime.run(
agent,
"Compare the top workflow orchestration tools for AI agents",
)
result.print_result()
In production, you separate the deploy step from the worker process. You deploy the agent once. You start runs and they live on the server, continuing even if your process goes away. You run workers in a separate long-lived process that picks up tool tasks. Every execution is visible in the Agentspan UI, every step is logged, and every LLM call is recorded.
That server-side runtime is the part the code sample does not show directly. Once the run starts, the server records the execution graph and keeps it available after the worker exits or the run finishes.
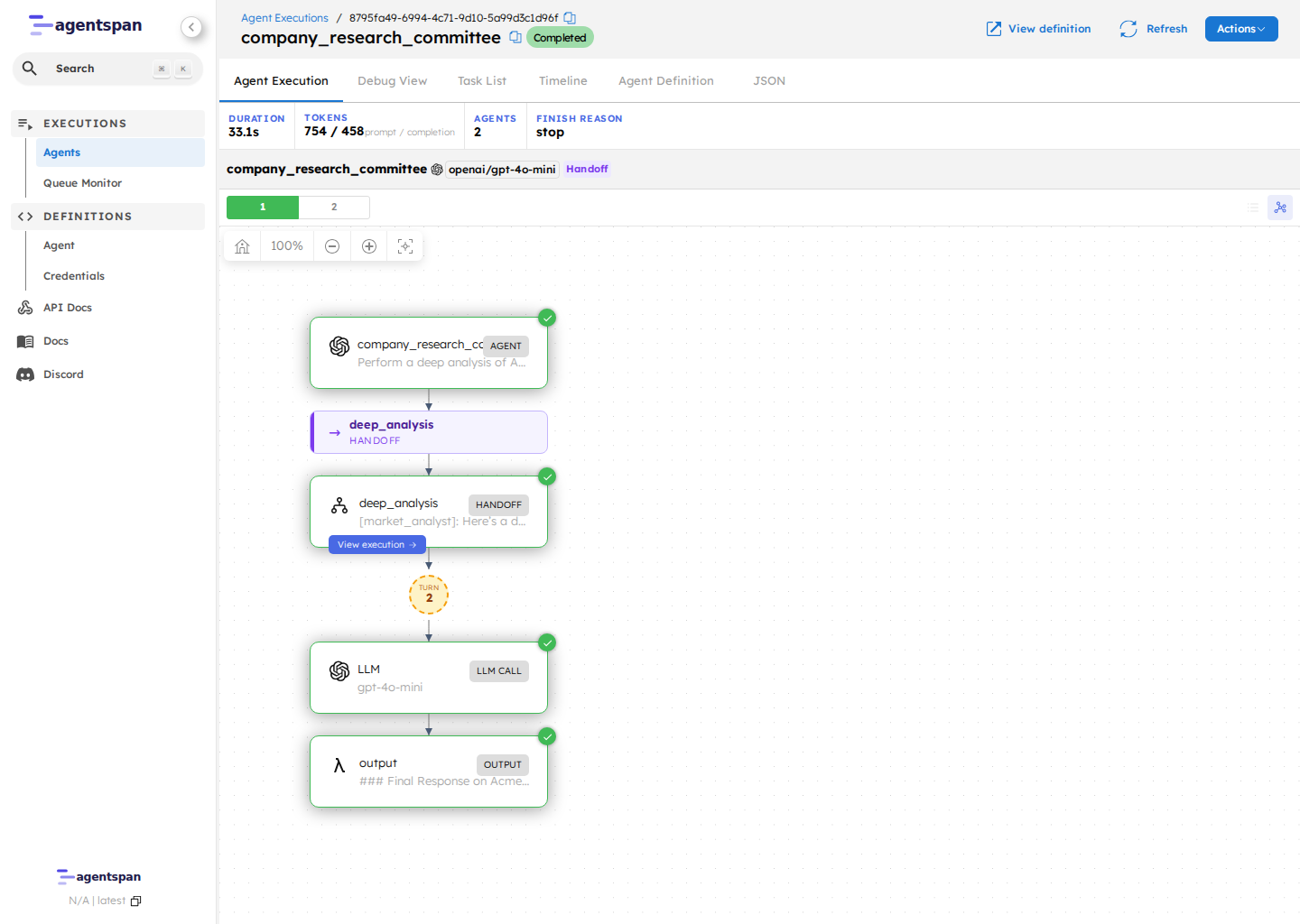
Example execution graph from the Agentspan UI.
The graph is what makes debugging different. You can inspect a completed or failed run and see the sequence of agent, LLM, and tool steps the server recorded, instead of reconstructing what happened from application logs.
What’s worth noting is that this isn’t magic. It’s the right execution model applied to a new problem. The engineering that made workflows reliable at Netflix scale turns out to be exactly what agents need to be reliable in production.
Get started
Install the SDK:
pip install agentspan
Start the Agentspan server locally using Docker Compose. Full setup instructions are in the Agentspan Quickstart. Once it’s running, point the SDK at it:
export AGENTSPAN_SERVER_URL=http://localhost:6767/api
export OPENAI_API_KEY=your-key-here
The code above runs as-is from there.
We built Agentspan because we kept seeing the same failure mode, agents that work in demos and break in production, and we had the foundation to fix it properly. Everything is open source and MIT licensed.
Try it at agentspan.ai. If you’re running agents in production and hitting reliability problems, I’d genuinely like to hear what you’re seeing.