AI Agent System Design: Building Durable Agents from Tools to Deployment
Ten years ago, the term “digital transformation” dominated marketing websites and consulting brochures. For many companies, the term represented real technical and architectural change: moving from on-prem infrastructure to the cloud, exposing legacy systems through APIs, and connecting systems that previously lived in silos.
For others, it became a vague way to say “we are modernizing with technology” while implementation stayed aspirational.
Agentic AI is following a similar pattern. The term is useful as a signal of strategic change, but it is too broad to distinguish a demo from a production system. That is partly why agentic AI language shows up on nearly every company website while the industry still lacks shared clarity about what it means to build a production-ready agentic stack.
What ultimately matters is outcomes. Not whether software is “agentic,” but whether it can coordinate tools, state, policy, humans, and recovery under failure. In other words: can agents be implemented durably as business-critical software?
What exactly are AI agents?
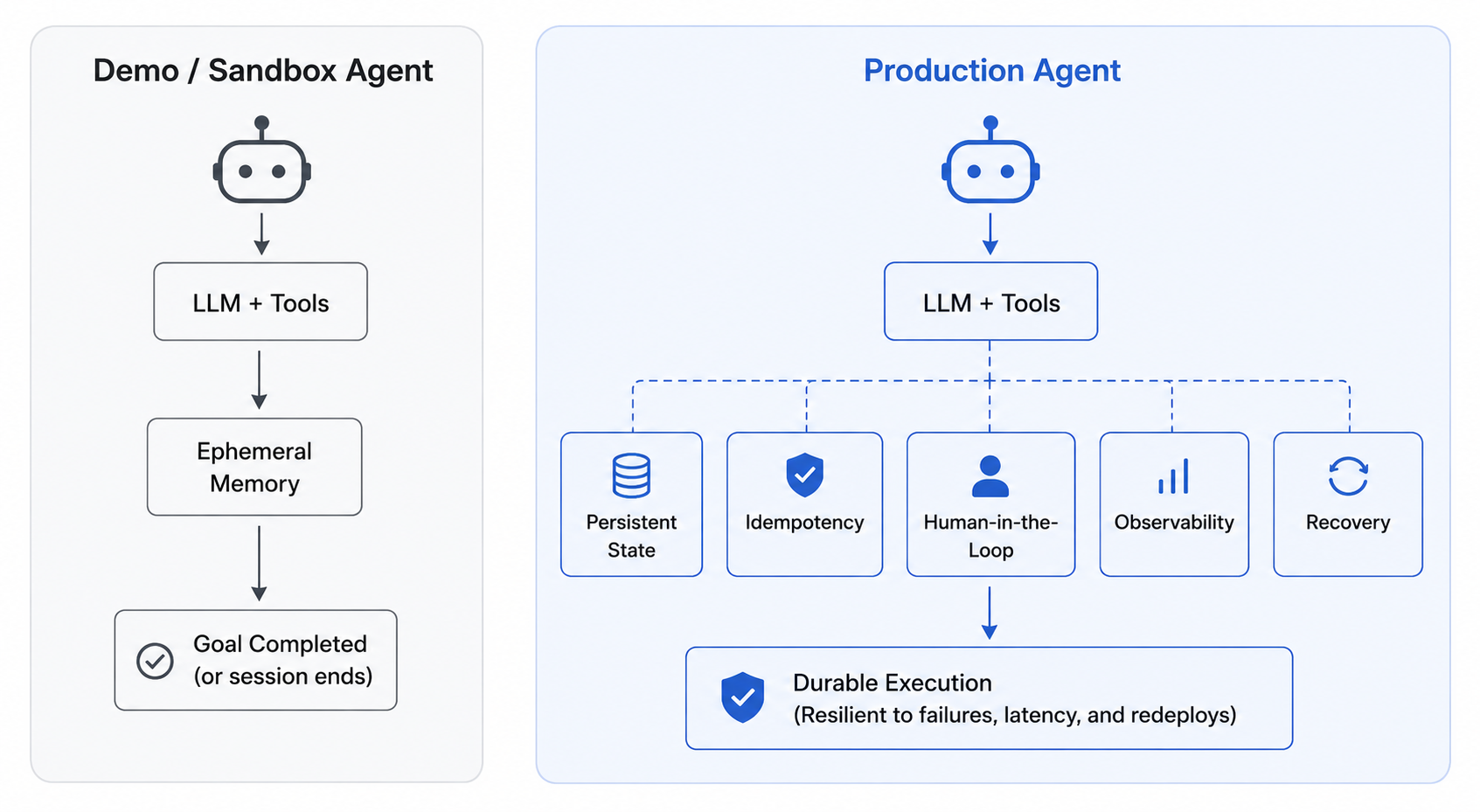
AI agents are often introduced as software that combines language models with tools and adapts its behavior until it completes a goal. That framing is useful for demos and sandboxed environments, but it is incomplete for production systems.
In production, AI agents are better understood as distributed execution systems with a model in the decision loop.
Many of the problems you need to solve are classical systems problems: state persistence, idempotency, human-in-the-loop suspension, observability, and recovery. Production AI agents require both reasoning and durability logic.
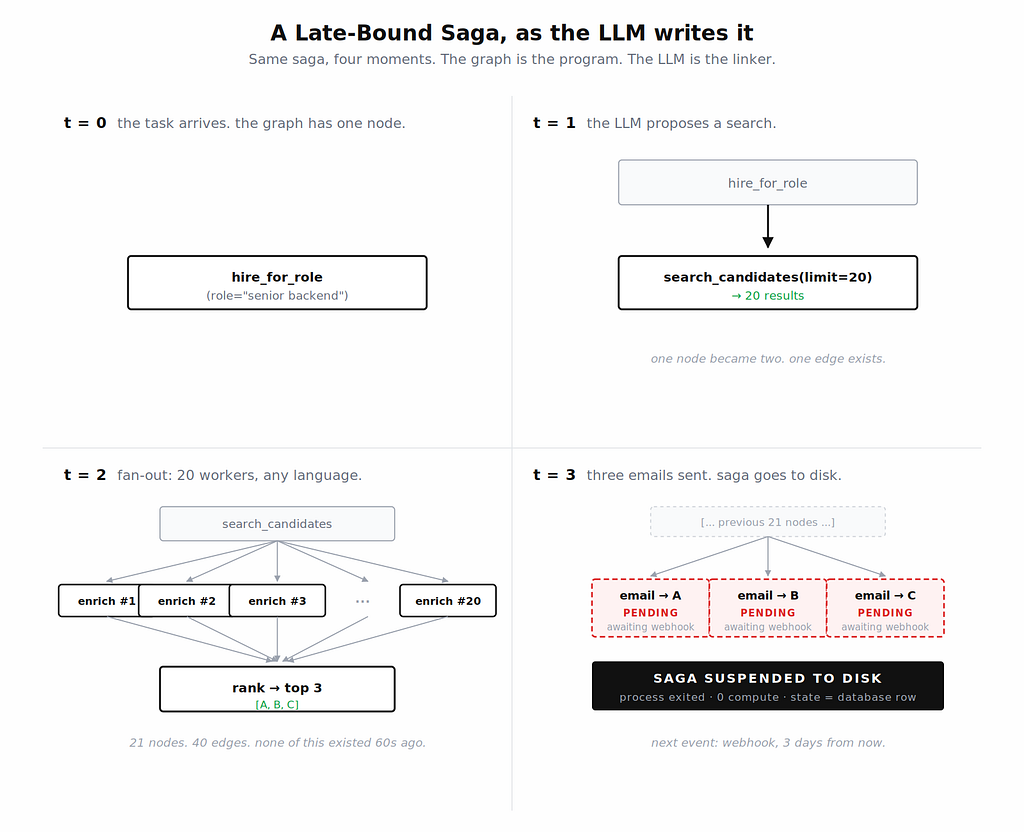
Put differently: an isolated AI agent system is successful if the agent completes its task. A production-grade system is successful if it can survive process death, external API failure, human latency, and redeployment without corrupting its own state or the state of dependent systems.
The agent as a distributed execution graph
A production agent can be thought of as having six layers:
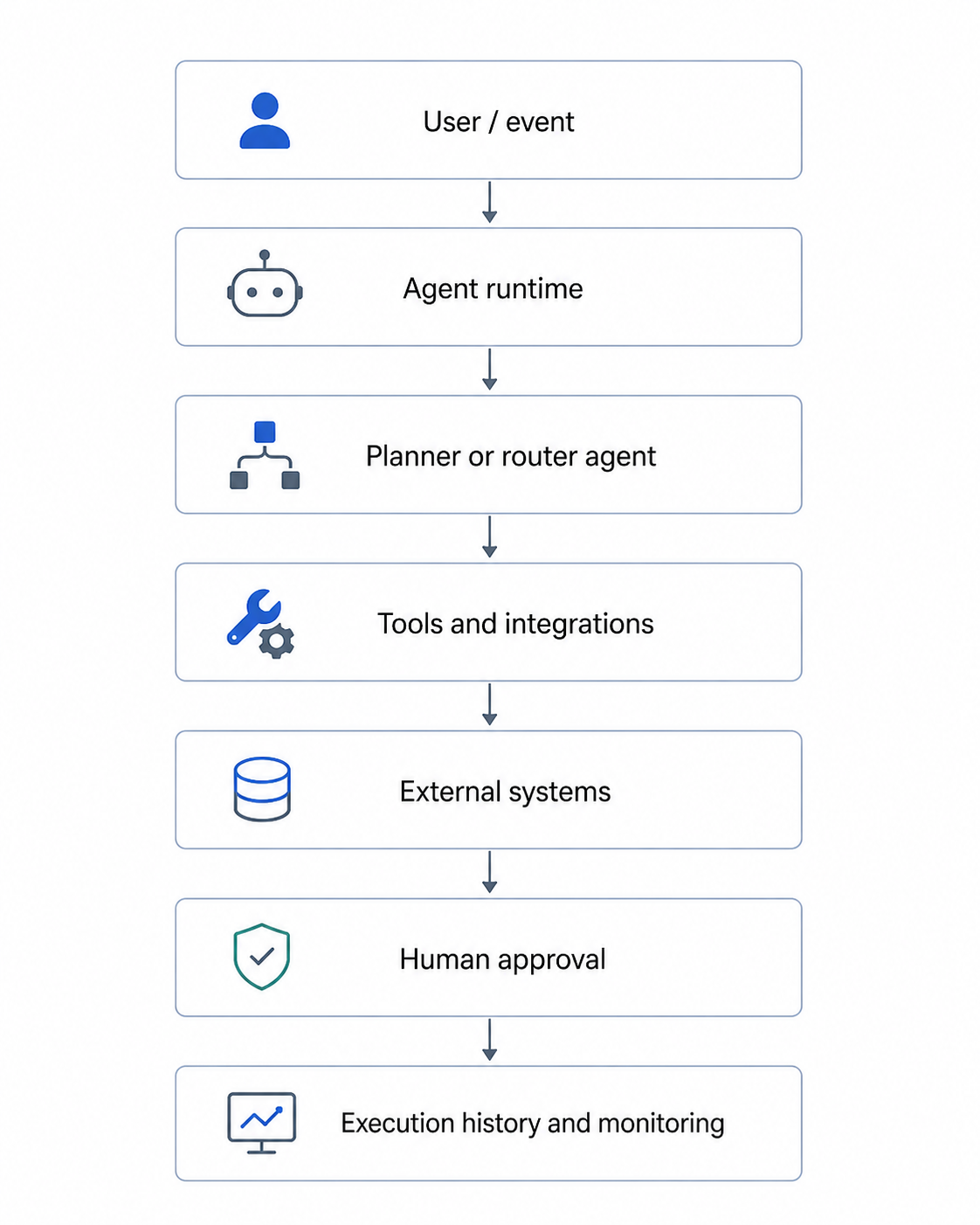
This architecture is closer to workflow orchestration than to a chatbot loop. The LLM can choose its actions, but the system must govern when those actions are executed, retried, paused, audited, or rejected.
Consider how the following Python code interacts with some of these layers:
from agentspan.agents import Agent, AgentRuntime, tool
@tool
def lookup_customer(email: str) -> dict:
"""Read-only lookup against CRM."""
return {
"email": email,
"tier": "enterprise",
"status": "active",
}
agent = Agent(
name="provisioning_architect",
model="openai/gpt-4o",
tools=[lookup_customer],
instructions=(
"Provision enterprise customers safely. "
"First inspect the customer record, then decide the next step."
),
)
with AgentRuntime() as runtime:
result = runtime.run(
agent,
"Provision alice@example.com for enterprise onboarding",
)
observability.emit({
"status": str(result.status),
"output": result.output,
"event_count": len(result.events),
"correlation_id": result.correlation_id,
})
Instead of being an invisible step inside a transient model interaction, the CRM lookup is a managed operation with identity, inputs, outputs, and history. The system can see what the agent did, recover if something fails, and continue the work instead of treating the interaction as a one-off reply.
Integrations define the failure surface
In agent systems, integrations are where things tend to break.
A real workflow might connect to a CRM, billing system, product API, Slack or Teams, a document database, and an approval tool. Each behaves differently. A CRM record might be outdated. A billing request might succeed only halfway. An API might slow down because of rate limits. A login token might expire even if the agent made the right decision.
That means the agent cannot treat every tool call the same way. Some systems are used only for information. Others change important business records. Some actions can be retried safely, while others might create duplicates, charge a customer twice, or send the wrong notification.
The key design questions are:
- Which system is the source of truth?
- Which actions can be retried safely?
- Which actions are risky enough that a human or policy check should approve them first?
The following example exposes a billing system through an explicit OpenAPI specification. Credentials are handled outside the model prompt, the imported API surface is bounded, and the agent is instructed to treat billing as a high-risk system.
from agentspan.agents import Agent, api_tool
billing = api_tool(
url="https://billing.example.com/openapi.json",
headers={"Authorization": "Bearer ${BILLING_API_KEY}"},
credentials=["BILLING_API_KEY"],
max_tools=20,
)
agent = Agent(
name="billing_operator",
model="openai/gpt-4o",
tools=[billing],
instructions=(
"Use billing APIs conservatively. "
"Never create charges without approval."
),
)
The agent can use the billing integration, but the system design constrains how it uses it.
Tool design: make side effects survivable
Once an agent can use a tool, it can take actions in other systems. That creates a design problem: the agent’s decisions can now change real business state.
The system must decide how each action should behave if something goes wrong. What if the tool runs twice? What if it runs late? What if it fails halfway through? What if the agent has the right goal but not enough context?
Different tools carry different levels of risk. A lookup tool is usually low-risk: if the agent checks a customer record twice, little changes. A tool that writes data needs more care. If the agent creates a workspace twice, the system may end up with duplicate accounts unless the request uses a stable ID.
Other actions need stricter controls. Charging a customer, deleting data, or sending an external message should create an audit trail, and in many cases should wait for human approval before running.
This distinction shows up directly in tool design. A workspace creation tool changes state, but it can be made safer with an idempotency key. A billing tool changes something more sensitive, so the system should pause for approval before running it.
from agentspan.agents import ToolContext, tool
@tool
def create_workspace(customer_id: str, context: ToolContext) -> dict:
"""
Create a workspace for a customer.
If the worker crashes and the tool is retried, the stable
idempotency key prevents duplicate workspaces for the same customer.
"""
idempotency_key = f"{context.workflow_id}:create_workspace:{customer_id}"
product_api = context.dependencies["product_api"]
return product_api.create_workspace(
customer_id=customer_id,
idempotency_key=idempotency_key,
)
@tool(approval_required=True, timeout_seconds=60)
def enable_paid_plan(
customer_id: str,
plan: str,
context: ToolContext,
) -> dict:
"""
Enable a paid plan for a customer.
This is higher-risk because it may affect billing. The agent can
request the action, but the runtime pauses for approval before
the tool actually runs.
"""
billing = context.dependencies["billing"]
return billing.enable_plan(
customer_id=customer_id,
plan=plan,
)
The two tools have different failure models. Creating a workspace can be retried safely if the external API honors the idempotency key. Enabling a paid plan should pass through an approval step first. This is how tool design turns abstract agent behavior into controlled system behavior.
Multi-agent strategies are control-flow policies
When a workflow uses more than one agent, the next design goal is to model how decision-making moves through the overall system.
Some work should happen in a fixed order. For example: check a customer, create a workspace, notify the team, then write a summary.
Some work can happen at the same time. The agent might check CRM, billing, permissions, and documentation in parallel because none of those checks depends on the others.
Other workflows need routing. A router can send billing issues to a billing agent, technical issues to a technical agent, and unclear requests to a general agent. In more sensitive workflows, a manual strategy can pause the process until a person chooses what should happen next.
from agentspan.agents import Agent, Strategy
intake = Agent(
name="intake",
tools=[lookup_customer],
instructions="Look up the customer and classify the provisioning request.",
)
billing_check = Agent(
name="billing_check",
tools=[check_billing_status],
instructions="Check whether the customer is eligible for paid-plan setup.",
)
permissions_check = Agent(
name="permissions_check",
tools=[check_admin_permissions],
instructions="Check whether the requesting user has admin permissions.",
)
docs_check = Agent(
name="docs_check",
tools=[lookup_contract_terms],
instructions="Check whether the contract allows this workspace configuration.",
)
planner = Agent(
name="planner",
instructions="Review all checks and decide which provisioning steps are allowed.",
)
executor = Agent(
name="executor",
tools=[create_workspace, enable_paid_plan],
instructions="Run only the provisioning actions approved by the planner.",
)
enterprise_checks = Agent(
name="enterprise_checks",
agents=[billing_check, permissions_check, docs_check],
strategy=Strategy.PARALLEL,
)
standard_setup = planner >> executor
enterprise_setup = enterprise_checks >> planner >> executor
billing_review = billing_check >> planner >> executor
classifier = Agent(
name="provisioning_classifier",
model="openai/gpt-4o-mini",
instructions=(
"Classify the request as standard_setup, enterprise_setup, "
"or billing_review. Reply with only the selected route name."
),
)
workflow = intake >> Agent(
name="provisioning_router",
agents=[standard_setup, enterprise_setup, billing_review],
strategy=Strategy.ROUTER,
router=classifier,
)
This example combines multiple strategies because real workflows rarely follow one pattern. The router chooses which workflow path the request should follow. After that, each path defines the order of work: some steps run in parallel, while others run sequentially. The individual agents can still reason about their tasks, but the workflow defines how work is allowed to move through the system.
The deployment infrastructure behind durable agents
A local agent demo can run in one process on a laptop. Production agents need more structure. The workflow may call several APIs, wait for a human decision, or retry failed tools. That usually requires several infrastructure pieces working together.
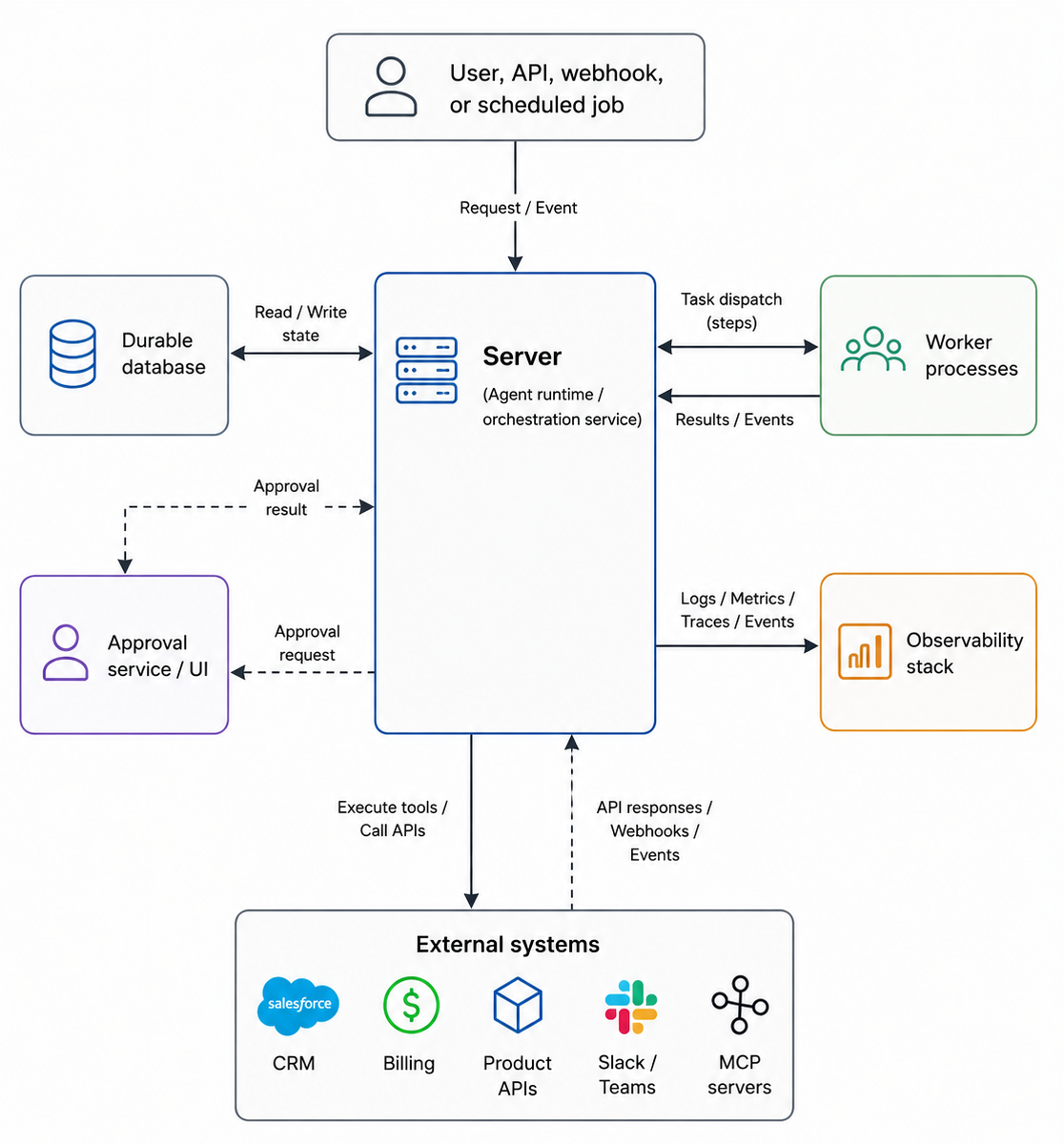
The entry point is how work begins. It might be a user message, API request, webhook, queue event, or scheduled job. This creates a new execution that the system can track.
The server runtime coordinates the workflow. It decides which agent or tool should run next, records progress, handles waiting states, and resumes the workflow after failures.
A persistent database stores the state of the work. This includes the current step, completed tool calls, failed attempts, approval status, and final output. If a container restarts, this database is how the system remembers what already happened.
Workers perform the actual tool calls. They might run Python functions, call internal services, or connect to third-party APIs. Workers should be replaceable. If one dies, another worker should be able to continue from the stored execution state.
The approval layer handles actions that should not run automatically, such as enabling billing, deleting data, or sending an external notification. The workflow can pause here without losing its place.
The observability stack gives operators a way to inspect the system. Logs show process details, metrics show system health, traces show timing, and execution history shows the business-level path the agent took.
This setup changes the failure model. If a worker disappears, the workflow should not disappear with it. The runtime still knows which step was active, which tools already ran, and what needs to happen next. Production agents need this separation because the work has to survive beyond any single process, container, or machine.
Build durable agents with Agentspan
The next generation of AI agent architecture will be judged less by whether an LLM can select a tool and more by whether the surrounding system can preserve state under failure.
Durable agents are distributed systems with language-model planners inside them. They need stable execution identity, recoverable state, safe tool semantics, human suspension, scalable workers, and observable history.
The systems problems described above are exactly the problems Agentspan is built around. Agentspan is an open-source distributed runtime for AI agents that keeps executions alive beyond a single process, supports distributed tool workers, pauses durably for human approval, and records execution history for debugging and monitoring.
You can define native Agentspan agents or bring agents from frameworks like LangGraph, OpenAI Agents SDK, or Google ADK, then run them with crash recovery, human-in-the-loop pauses, and execution history.
Do not only ask whether your agent can reason. Ask whether the system can recover. Get started with Agentspan, and join our Discord community to stay in the loop.