Three Reviewers, Two Rounds, One Verdict: Build a Code Review Debate with Round Robin
This is Part 5 of an 8-part series covering every multi-agent strategy in Agentspan. Today: the round robin strategy, where agents take turns in a fixed rotation and each agent builds on what the others said.
In Part 1, we built a sequential pipeline where each agent’s output fed into the next. In Part 2, we built a parallel code review where three reviewers ran simultaneously. In Part 3, the LLM decided which agent ran. In Part 4, agents transferred work between each other peer-to-peer.
Every strategy so far either runs agents once or lets someone decide who goes next: a parent, a classifier, or the agents themselves. But some work benefits from a fixed discussion pattern where every agent gets a turn, then gets another turn after seeing what the others said.
That is the round robin strategy. No routing. No decision about who goes next. Just a fixed rotation: A, B, C, A, B, C. Each agent sees the full conversation history and builds on it.
What is Agentspan?
Agentspan is an orchestration layer for building, bringing, and observing AI agents as durable workflows.
- Build: define agents with the Agentspan SDK using
Agent,@tool, and multi-agent strategies. Agentspan compiles them into server-side workflows that survive crashes. - Bring: if you already use frameworks such as LangGraph, OpenAI Agents SDK, or Google ADK, you can run those agents through Agentspan and add durability and orchestration on top.
- Observe: every execution is inspectable in the dashboard. You can see agent flows, inputs, outputs, tool calls, token usage, and failures.
Setup
Two commands:
pip install agentspan
agentspan server start
This starts a local Agentspan server with a dashboard at http://localhost:6767.
What we are building
A code review debate with three reviewers who take turns:
- Architect: focuses on design, structure, and scalability
- Security Reviewer: focuses on vulnerabilities, data exposure, and insecure defaults
- Pragmatist: focuses on what actually matters for shipping: minimum fix, what can wait
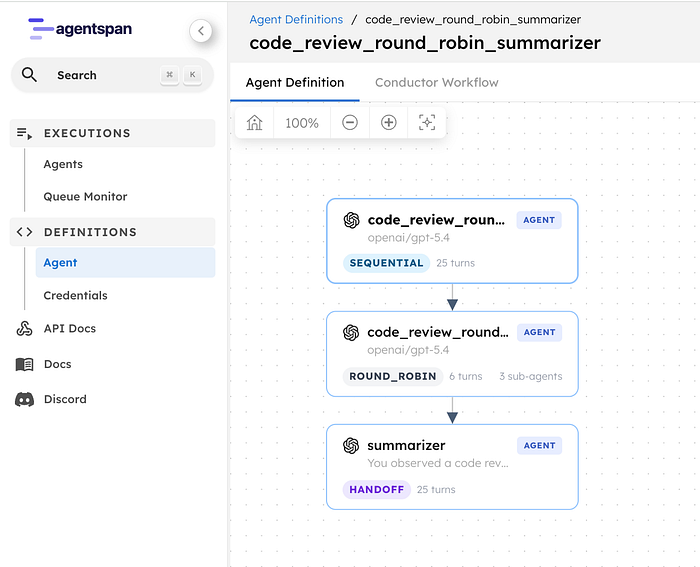
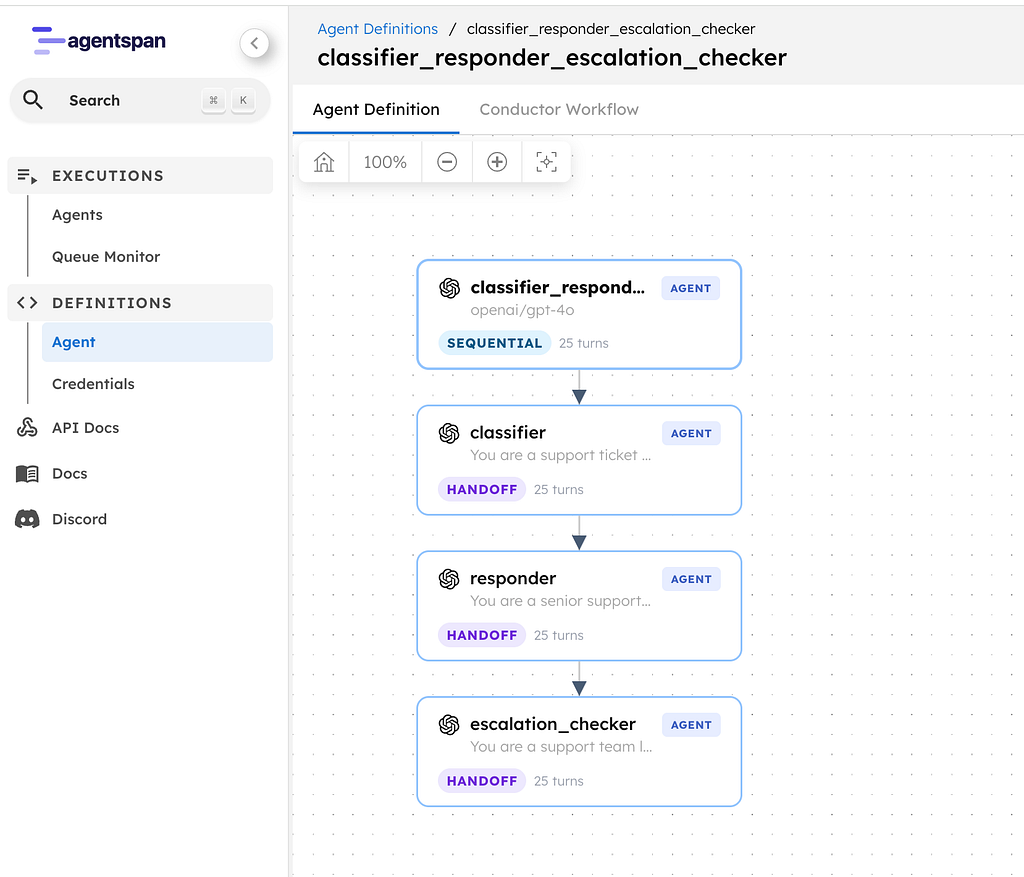
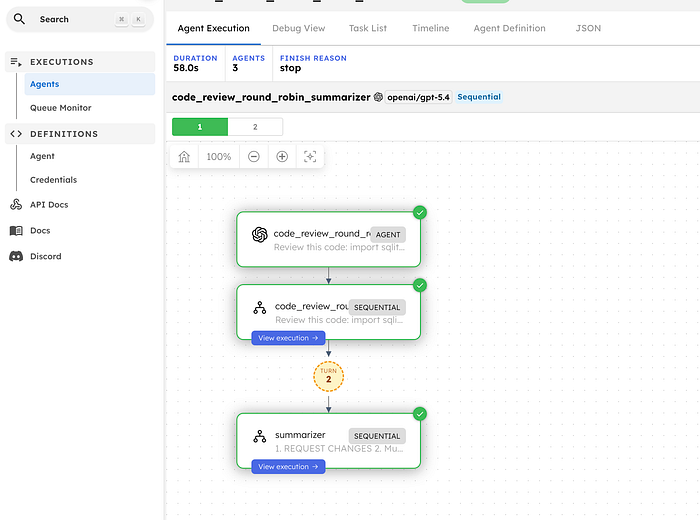
The workflow has three reviewer personas and a summarizer. Round robin controls the reviewer turn order before the final verdict is produced.
They review the same code. Unlike parallel execution, where each reviewer works independently, round robin reviewers read each other’s comments and respond to them. The architect raises a design concern. The security reviewer agrees and adds a vulnerability. The pragmatist pushes back: “that is a follow-up PR, not a blocker.” Two rounds of this, then a summarizer produces the verdict.
Round 1: [Architect] -> [Security] -> [Pragmatist]
Round 2: [Architect] -> [Security] -> [Pragmatist]
|
v
[Summarizer] -> APPROVE / REQUEST CHANGES
How is this different from parallel?
In parallel, all three reviewers run at the same time on the same input. They never see each other’s work. You get three independent opinions.
In round robin, reviewers take turns. Each one sees the full conversation, including what previous reviewers said. The second-round architect can respond to what the pragmatist said in round one. It is a discussion, not three monologues.
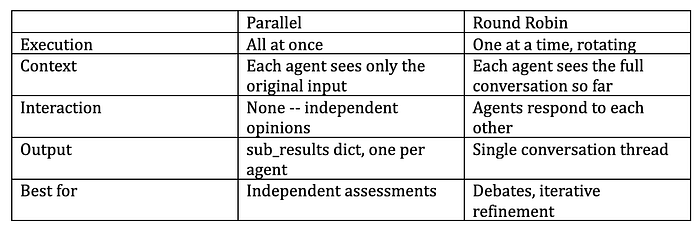
Parallel produces independent opinions. Round robin produces a shared discussion where each reviewer sees what came before.
Defining the reviewers
Three agents, each with a different perspective:
from agentspan.agents import Agent, AgentRuntime, Strategy
architect = Agent(
name="architect",
model="openai/gpt-4o",
instructions=(
"You are a software architect reviewing code. Focus on:\n"
"- Design patterns and structure\n"
"- Separation of concerns\n"
"- Scalability and maintainability\n\n"
"Read what other reviewers said before you. Build on their points, "
"do not repeat them. Keep your response to 2-3 paragraphs."
),
)
The security reviewer looks at the same conversation, but with a different lens:
security_reviewer = Agent(
name="security_reviewer",
model="openai/gpt-4o",
instructions=(
"You are a security engineer reviewing code. Focus on:\n"
"- Injection vulnerabilities: SQL, command, path traversal\n"
"- Authentication and authorization gaps\n"
"- Data exposure and insecure defaults\n\n"
"Read what other reviewers said before you. Build on their points, "
"do not repeat them. Keep your response to 2-3 paragraphs."
),
)
The pragmatist’s job is to separate blockers from follow-up work:
pragmatist = Agent(
name="pragmatist",
model="openai/gpt-4o",
instructions=(
"You are a senior engineer who values shipping. Focus on:\n"
"- Is this good enough to merge today?\n"
"- What is the minimum fix needed?\n"
"- What can wait for a follow-up PR?\n\n"
"Push back on over-engineering. Read what other reviewers said "
"and decide what actually matters for this PR. "
"Keep your response to 2-3 paragraphs."
),
)
The key instruction in each reviewer is: read what other reviewers said before you, then build on their points. That is what makes round robin a discussion rather than repetition.
The summarizer
After the debate, a summarizer reads the entire transcript and produces a verdict:
summarizer = Agent(
name="summarizer",
model="openai/gpt-4o",
instructions=(
"You observed a code review discussion between an architect, "
"a security reviewer, and a pragmatist. Produce a final verdict:\n\n"
"1. APPROVE, REQUEST CHANGES, or NEEDS DISCUSSION\n"
"2. Must-fix items that block merge\n"
"3. Nice-to-have items for a follow-up PR\n"
"4. One-sentence summary\n\n"
"Be decisive. Do not hedge."
),
)
The round robin strategy
The team agent uses Strategy.ROUND_ROBIN and a max_turns limit:
review = Agent(
name="code_review_round_robin",
model="openai/gpt-4o",
agents=[architect, security_reviewer, pragmatist],
strategy=Strategy.ROUND_ROBIN,
max_turns=6,
)
pipeline = review >> summarizer
max_turns=6 means six total turns: architect, security reviewer, pragmatist, architect, security reviewer, pragmatist. That is two full rounds. Then >> pipes the discussion transcript to the summarizer.
The round robin strategy uses the same Agent primitive, but changes how the child agents are scheduled.
Compare the strategies:
# Sequential: fixed order, each runs once
pipeline = a >> b >> c
# Parallel: all run at once
team = Agent(agents=[a, b, c], strategy=Strategy.PARALLEL)
# Handoff: parent LLM picks one
triage = Agent(agents=[a, b, c], strategy=Strategy.HANDOFF)
# Router: classifier picks one
triage = Agent(agents=[a, b, c], strategy=Strategy.ROUTER, router=classifier)
# Swarm: agents transfer between each other
team = Agent(agents=[a, b, c], strategy=Strategy.SWARM)
# Round robin: fixed rotation, agents respond to each other
debate = Agent(agents=[a, b, c], strategy=Strategy.ROUND_ROBIN, max_turns=6)
Same Agent class. Different strategy. Different behavior.
The code to review
A short Python snippet with design, security, and pragmatic tradeoffs:
import os
import sqlite3
def get_user(db_path, user_id):
conn = sqlite3.connect(db_path)
query = f"SELECT * FROM users WHERE id = {user_id}"
result = conn.execute(query).fetchone()
conn.close()
return result
def save_upload(filename, data):
path = f"/uploads/{filename}"
with open(path, "wb") as f:
f.write(data)
os.chmod(path, 0o777)
return path
def process_payment(amount, card_number):
print(f"Processing ${amount} on card {card_number}")
return {"status": "ok", "amount": amount}
There is SQL injection, path traversal, card data in logs, overly broad file permissions, and no error handling. The code is also short, easy to understand, and someone wants to merge it. The reviewers should not all respond the same way.
Running it
with AgentRuntime() as runtime:
result = runtime.run(pipeline, code)
result.print_result()
What happens
In round one, the architect sees the raw code and flags the lack of abstraction: no database layer, no upload service, and direct file-system access.
The security reviewer goes second. It sees the architect’s comments and the code, then adds the critical security findings: SQL injection in get_user, path traversal in save_upload, card number logging in process_payment, and 0o777 permissions.
The pragmatist goes third. It sees both previous reviews. It agrees that SQL injection and card logging are blockers, but pushes back on the larger architecture refactor: fix the security issues, merge, and refactor in a follow-up.
In round two, the architect can respond to that pushback. It may concede that the full refactor can wait, while still asking for a minimum cleanup such as using a context manager for the database connection.
The security reviewer can then clarify which issues are still merge blockers. The pragmatist can close the loop by naming the minimum set of changes required before the PR is safe to merge.
The summarizer reads the full transcript and produces the final verdict.
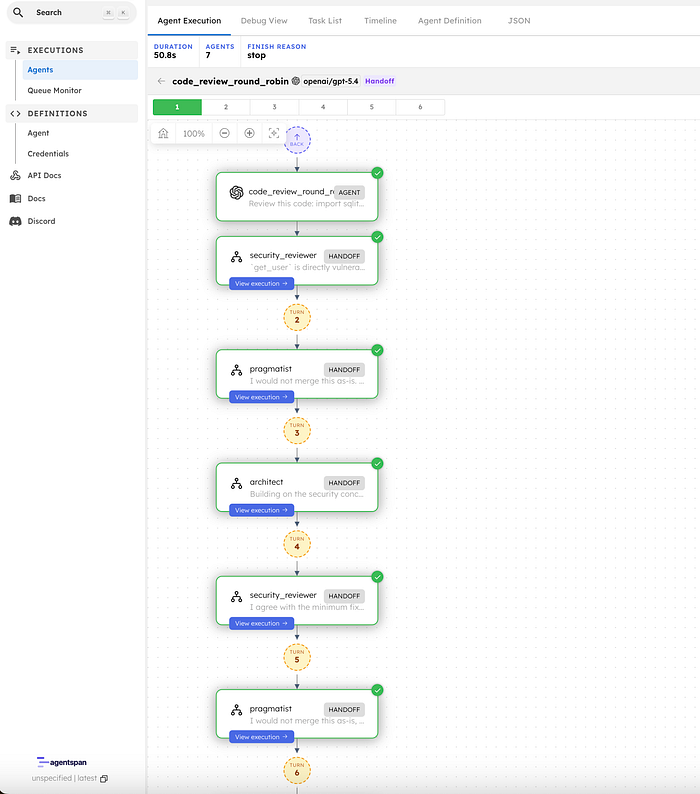
In the Agentspan UI, the run is visible as a durable execution with each reviewer turn recorded in order.

The summarizer produces the final review outcome after reading the full multi-turn discussion.
Round robin vs. parallel
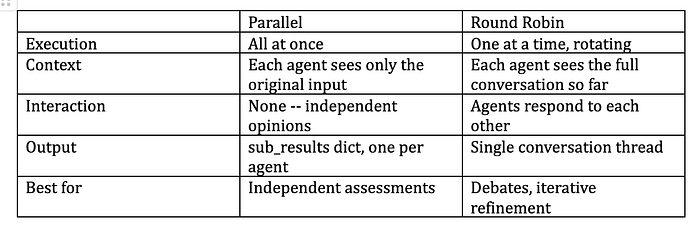
Use parallel when independent review is enough. Use round robin when the reviewers should respond to each other and converge.
Use parallel when speed matters and independence is useful. Each reviewer forms an opinion without being influenced by the others.
Use round robin when convergence matters. Each reviewer can challenge, refine, or accept what came before, and the team can move toward a shared recommendation.
How durability works
The round robin strategy compiles into a durable loop on the server. If your process crashes after turn four, the first four turns are persisted with the execution.
When you restart the worker, the execution can continue from the next turn in the rotation instead of starting the conversation over. Each turn is part of the durable execution history.
Composability
Round robin also composes with other strategies:
# Debate, then summarize
pipeline = review >> summarizer
# Parallel fan-out for data, then round robin debate on findings
research = Agent(
agents=[market, technical, financial],
strategy=Strategy.PARALLEL,
)
debate = Agent(
agents=[optimist, skeptic],
strategy=Strategy.ROUND_ROBIN,
max_turns=4,
)
pipeline = research >> debate >> summarizer
Parallel collects independent research. Round robin debates the findings. The summarizer produces the final recommendation.
Try it
pip install agentspan
agentspan server start
python 06_code_review_debate.py
- GitHub: github.com/agentspan-ai/agentspan
- Blog examples: round robin examples
- Docs: agentspan.ai/docs
What is next
Part 6: Random. A random agent is selected each turn. Not a rotation, not a decision, but randomness. This can be useful for creative brainstorming, load balancing across models, and generating diverse output ensembles.