You Decide: Build a Human-Directed Editorial Workflow with the Manual Strategy
This is Part 7 of an 8-part series covering every multi-agent strategy in Agentspan. Today: the manual strategy — the human picks which agent speaks next. Full control.
In Part 1, agents ran in a fixed order. In Part 2, all agents ran at once. In Part 3, the LLM decided who runs. In Part 4, agents decided among themselves. In Part 5, agents took fixed turns. In Part 6, agents were selected randomly.
Every strategy so far has one thing in common: something other than the human decided which agent runs next — the pipeline, the LLM, the classifier, the rotation, or randomness.
That is the manual strategy. The human picks. Every turn, the workflow pauses and asks: which agent should go next? The human makes the call.
What is Agentspan?
Agentspan is an orchestration layer for building, bringing, and observing AI agents as durable workflows.
- Build: define agents with the Agentspan SDK using
Agent,@tool, and multi-agent strategies. Agentspan compiles them into server-side workflows that survive crashes. - Bring: if you already use frameworks such as LangGraph, OpenAI Agents SDK, or Google ADK, you can run those agents through Agentspan and add durability and orchestration on top.
- Observe: every execution is inspectable in the dashboard. You can see agent flows, inputs, outputs, tool calls, token usage, and failures.
Setup
Two commands:
pip install agentspan
agentspan server start
This starts a local Agentspan server with a dashboard at http://localhost:6767.
What we are building
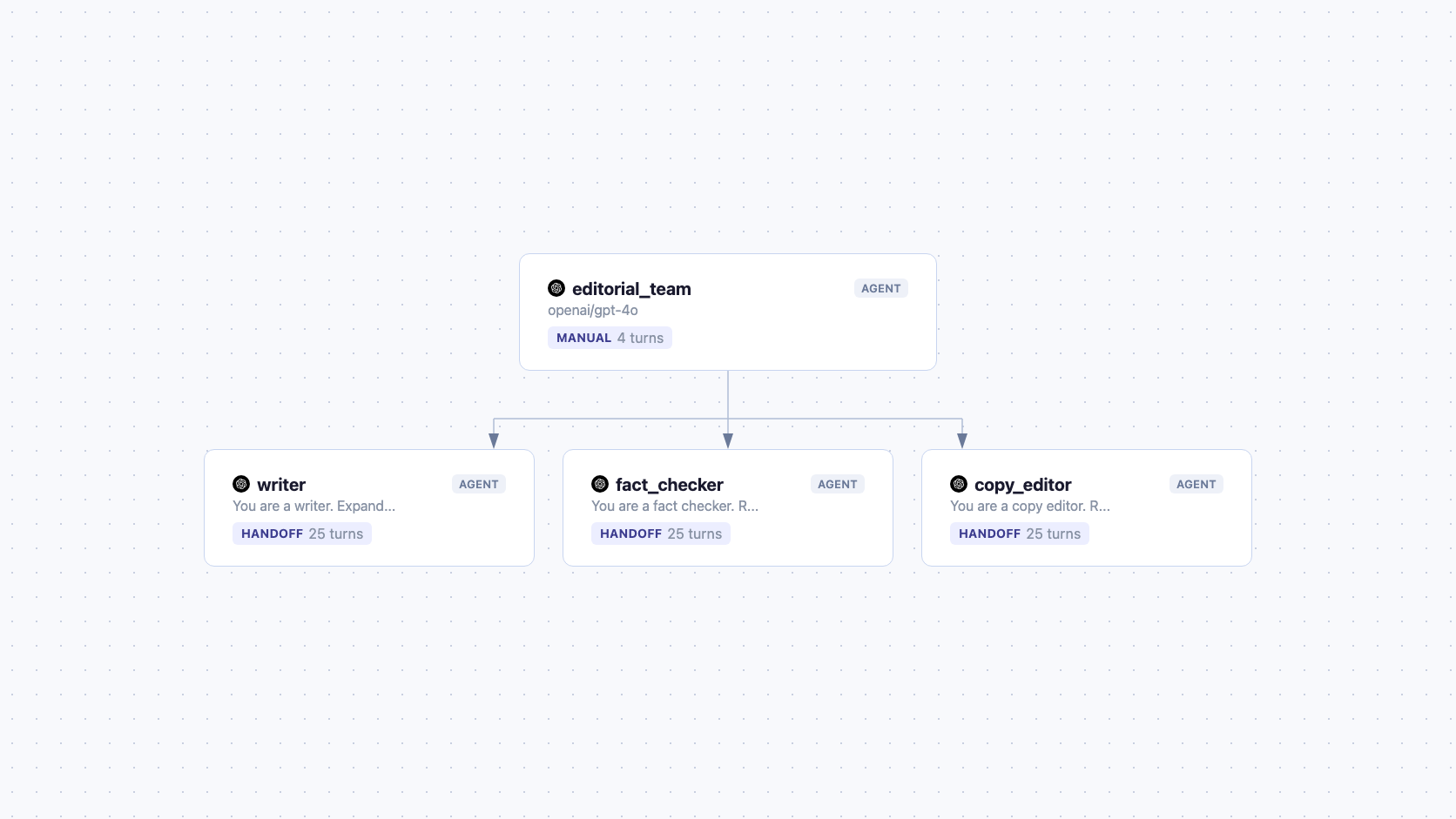
An editorial workflow with three specialists:
- Writer: drafts and revises content
- Fact Checker: verifies accuracy, flags unsupported claims
- Copy Editor: fixes grammar, tightens prose, improves flow
The human editor directs the workflow. Maybe the writer goes first, then the fact checker, then back to the writer for revisions, then the copy editor for polish. The human decides the sequence based on what the draft needs — not a predetermined pipeline.
Human picks: writer
-> [Writer] drafts content
Human picks: fact_checker
-> [Fact Checker] flags issues
Human picks: writer
-> [Writer] revises based on feedback
Human picks: copy_editor
-> [Copy Editor] polishes final version
How is this different from everything else?
| Strategy | Who decides what runs next |
|---|---|
| Sequential | Nobody — fixed order |
| Parallel | Nobody — all at once |
| Handoff | The parent LLM |
| Router | A classifier agent or function |
| Swarm | The agents themselves |
| Round Robin | Fixed rotation |
| Random | Randomness |
| Manual | The human |
Manual is the only strategy where a human is in the orchestration loop — not just approving tool calls (that is HITL), but actively directing which agent runs.
Defining the specialists
Three agents with editorial roles:
from agentspan.agents import Agent, AgentRuntime, Strategy, EventType
writer = Agent(
name="writer",
model="openai/gpt-4o",
instructions=(
"You are a writer. Expand on ideas with clear, engaging prose. "
"If you receive feedback from other agents, revise your work "
"based on their suggestions. Keep your response focused and concise."
),
)
fact_checker = Agent(
name="fact_checker",
model="openai/gpt-4o",
instructions=(
"You are a fact checker. Review the content for accuracy. "
"Flag any claims that are unsupported, exaggerated, or wrong. "
"Be specific — quote the exact text and explain the issue. "
"If everything checks out, say so."
),
)
copy_editor = Agent(
name="copy_editor",
model="openai/gpt-4o",
instructions=(
"You are a copy editor. Review the content for grammar, clarity, "
"tone, and flow. Suggest specific edits. Tighten prose. Remove "
"filler. Make it read well. Return the improved version."
),
)
Each agent sees the full conversation — including what other agents said before them. The writer can revise based on the fact checker’s feedback. The copy editor polishes after everyone else is done.
The manual strategy
team = Agent(
name="editorial_team",
model="openai/gpt-4o",
agents=[writer, fact_checker, copy_editor],
strategy=Strategy.MANUAL,
max_turns=4,
)
No router. No classifier. No rotation. The workflow pauses at each turn and waits for the human to pick.
Compare all eight strategies:
# Sequential: fixed order, each runs once
pipeline = a >> b >> c
# Parallel: all run at once
team = Agent(agents=[a, b, c], strategy=Strategy.PARALLEL)
# Handoff: parent LLM picks one
triage = Agent(agents=[a, b, c], strategy=Strategy.HANDOFF)
# Router: classifier picks one
triage = Agent(agents=[a, b, c], strategy=Strategy.ROUTER, router=classifier)
# Swarm: agents transfer between each other
team = Agent(agents=[a, b, c], strategy=Strategy.SWARM)
# Round robin: fixed rotation
debate = Agent(agents=[a, b, c], strategy=Strategy.ROUND_ROBIN, max_turns=6)
# Random: random selection each turn
brainstorm = Agent(agents=[a, b, c], strategy=Strategy.RANDOM, max_turns=6)
# Manual: human picks each turn
workflow = Agent(agents=[a, b, c], strategy=Strategy.MANUAL, max_turns=4)
Same Agent class. Eight strategies. One primitive.
Running it
with AgentRuntime() as runtime:
handle = runtime.start(
team, "Write a short paragraph about the history of artificial intelligence."
)
for event in handle.stream():
if event.type == EventType.WAITING:
print("Pick the next agent:")
choice = input("> ")
handle.respond({"selected": choice})
elif event.type == EventType.DONE:
print(event.output)
The workflow starts. Each turn, EventType.WAITING fires and the human types an agent name. handle.respond() sends the selection back to the server. The chosen agent runs, and the cycle repeats until max_turns.
Example session
Pick the next agent: writer, fact_checker, copy_editor
> writer
[Writer produces a draft about AI history]
Pick the next agent: writer, fact_checker, copy_editor
> fact_checker
[Fact checker reviews, flags one claim about the Dartmouth Conference date]
Pick the next agent: writer, fact_checker, copy_editor
> writer
[Writer revises the draft, fixes the flagged claim]
Pick the next agent: writer, fact_checker, copy_editor
> copy_editor
[Copy editor polishes grammar, tightens prose, returns final version]
The human directed the flow: write, check, revise, polish. A fixed pipeline could not do this — the human decided to send it back to the writer after the fact checker flagged an issue. That loop was a judgment call, not a predetermined step.
When to use manual
Manual is the right strategy when:
- Editorial workflows — human editors direct the review process based on what the content needs
- Training and education — a student directs which tutor agent to consult next
- Debugging — a developer manually directs diagnostic agents to investigate specific areas
- Quality gates — a human reviewer decides whether the output needs another pass or is ready
If the routing logic can be automated with rules, LLM judgment, or fixed order, use one of the other seven strategies. Manual is for when the human’s judgment is the routing logic.
How durability works
Same as every previous part. The workflow pauses durably on the server while waiting for the human’s selection. Kill the process. Come back an hour later. The workflow is still waiting. Respond via the CLI or reconnect from a new process:
agentspan agent respond <execution-id> --data '{"selected": "writer"}'
No timeout. No thread blocked. The server holds the state indefinitely.
What is next
Part 8: Router. A dedicated classifier agent decides which specialist runs — not the parent LLM, not a fixed order, but a separate lightweight model whose only job is routing. The final strategy in the series.
Try it
pip install agentspan
agentspan server start
python 08_editorial_manual.py
- GitHub: github.com/agentspan-ai/agentspan
- Blog examples: manual examples
- Docs: agentspan.ai/docs